Shaders(着色器)
如何在只有 X 和 Y 坐标的情况下绘制高保真图形?
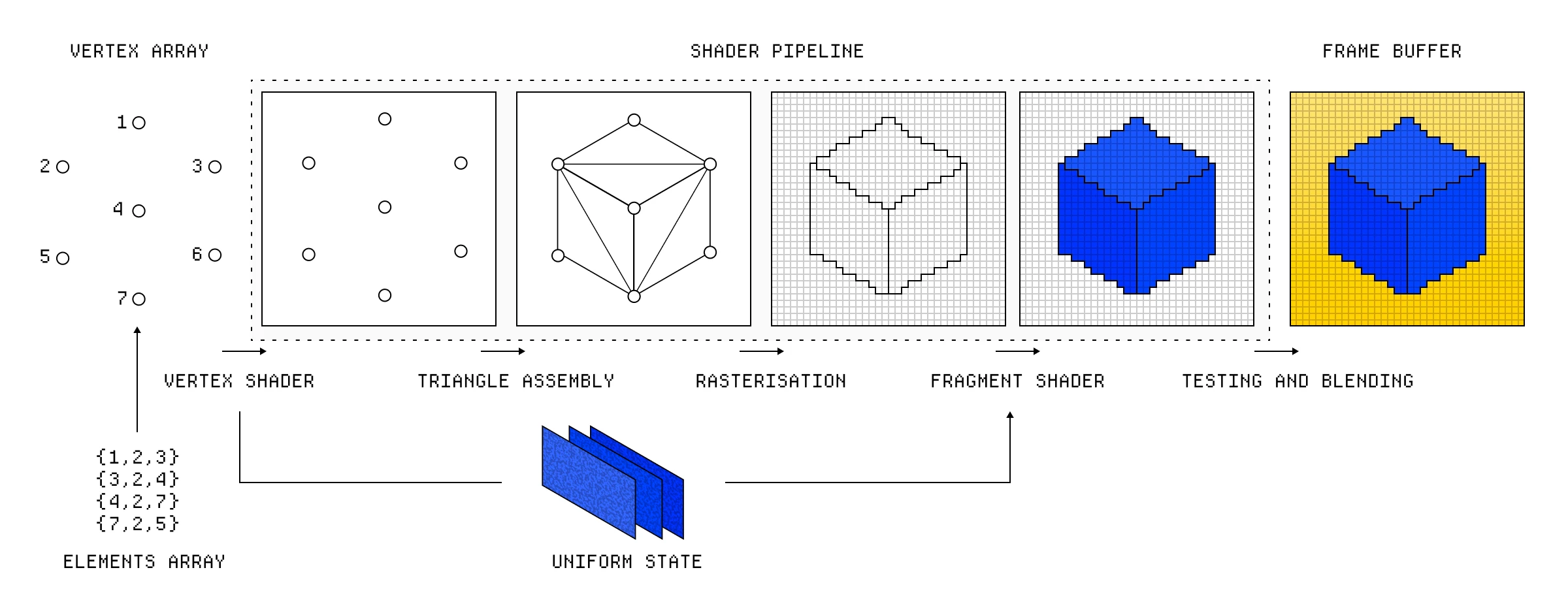
展示了不同阶段及其相互连接方式的着色器管线。
着色器(Shaders)是一个很好的例子,展示了限制如何激发人们的创造力——它们是在 GPU 上并行运行的简单程序,其目标是计算出单个像素的值。但是,每个着色器程序实例真正知道的只有一件事:它的 X 和 Y 位置。
那么,人们到底是如何仅凭一个 X 和 Y 坐标就创造出如此疯狂、高保真的图形的呢?简短的回答是数学。而不幸的是,详细的回答也将涉及一些数学。
什么是着色器? (What is a shader?)
让我们先搞清楚一点:着色器是一种设计用于在 GPU 上并行运行的程序。

一个网格渐变片段着色器。
当你想到着色器时,你可能会想象出一些迷幻的动画图形,但那些通常只是片段着色器,这只是着色器的一种类型。实际上有多种类型的着色器,它们在一个主要为渲染实时 3D 图形而设计的管线中协同工作。
这个管线的目标本质上是弄清楚场景中每个像素应该是什么颜色,而管线中的每一步都在将其传递给下一步之前计算其中的一小部分。但是,为什么我们根本需要着色器呢?
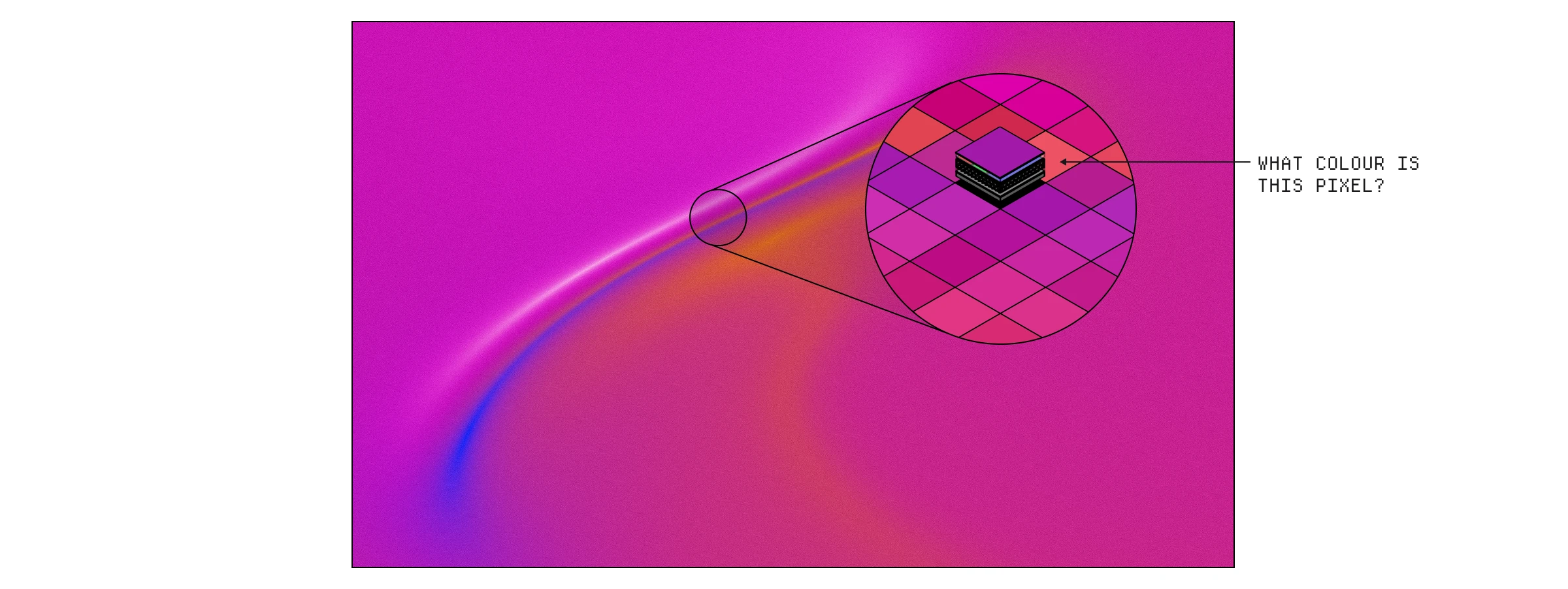
着色器管线的目标是确定每个像素的颜色。
在拥有着色器之前,开发人员实际上无法精细控制 GPU 应用光照和其他效果的方式。这被称为固定功能管线(Fixed Function Pipeline),在 2000 年代初期之前,所有消费级 GPU 都是这样出货的,带有一套相当固定的光照和渲染效果。
因此,着色器的设计目的是使图形管线可编程,允许开发人员直接在 GPU 上创建几乎任何他们想要的效果。从那时起,着色器已经突破了游戏引擎的世界,进入了像 Web 这样的领域。
但是着色器可能有点令人生畏,因为在 GPU 上编程与事情按顺序发生的“正常”编程略有不同。
GPU 是如何工作的 (How a GPU works)
因为着色器在 GPU 上运行,在深入了解它们如何工作之前,我们需要对它们所设计的环境多一点了解。
在计算的早期,计算机根本没有屏幕——它们只是打印输出——所以当 GUI(图形用户界面)出现时,它们给负责更新显示像素值的 CPU 增加了大量额外需求。
更新屏幕对 CPU 来说是一件烦人的工作——弄清楚一个像素应该是什么颜色并不特别困难,但有大量的像素,而且它们需要频繁更新。CPU 的设计目的是做几乎完全相反的事情——尽可能快地执行一个可能很复杂的任务,然后再进行下一个。
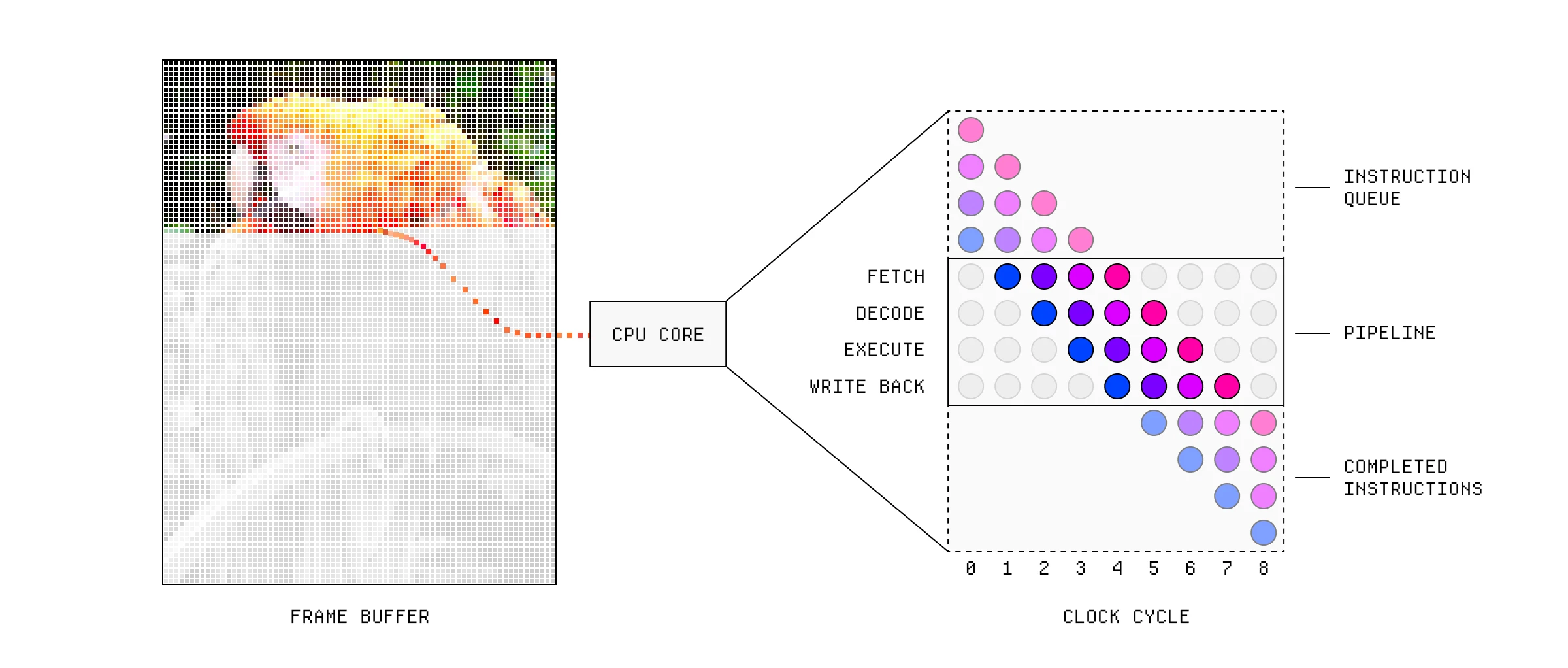
每个 CPU 核心在一个顺序管线中处理指令。
因此,硬件公司意识到需要专用硬件来更新帧缓冲区并与视频控制器通信。经过几十年的发展,这演变成了我们现在所说的 GPU——专门设计用于尽可能快地更新像素阵列的独立硬件。
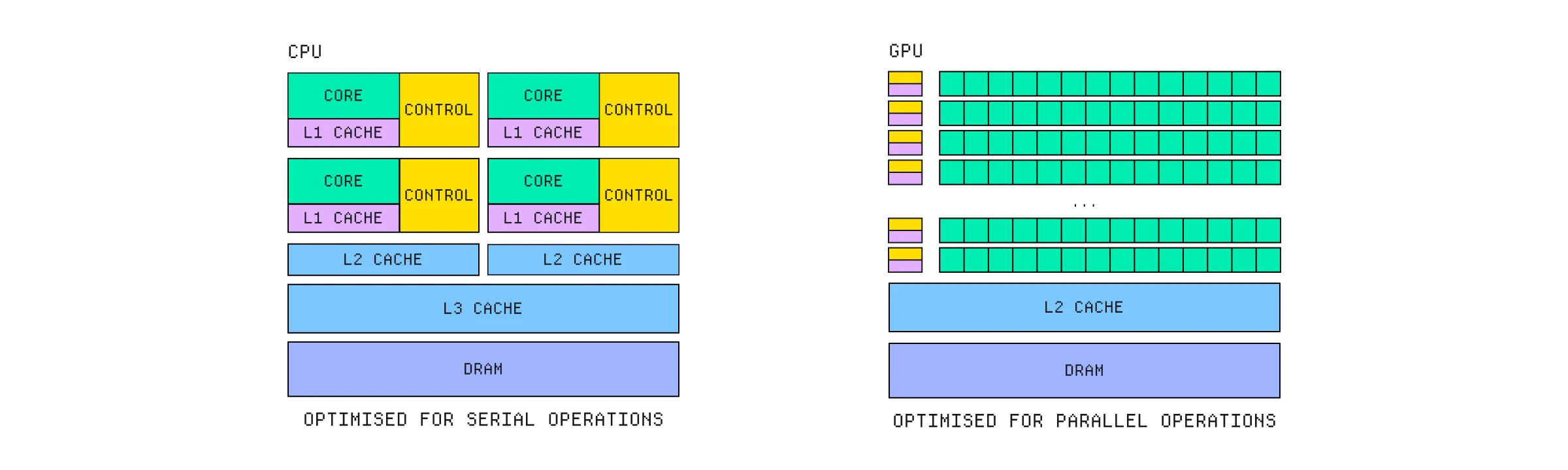
GPU 将比控制单元更多的资源用于计算和内存。
因为它们是专门为此目的设计的,所以它们可以做出一些更通用的 CPU 无法做出的权衡。CPU 旨在最小化延迟,或者换句话说,尽可能快地处理单个指令流。它们拥有少量真正强大的核心,以超快的时钟速度运行,并能进行巧妙的预测以确保几乎不浪费任何周期。
GPU 做出了相反的权衡,最大化吞吐量而不是延迟,利用数千个小型、简单且相对较慢的核心来处理尽可能多的指令。任何单条指令的处理速度都比在 CPU 上慢,但它可以通过同时处理海量指令来在每秒内完成更多的指令。
现代多核 CPU 每秒可以处理大约一千亿条指令,但现代 GPU 每秒可以处理数十万亿条指令。
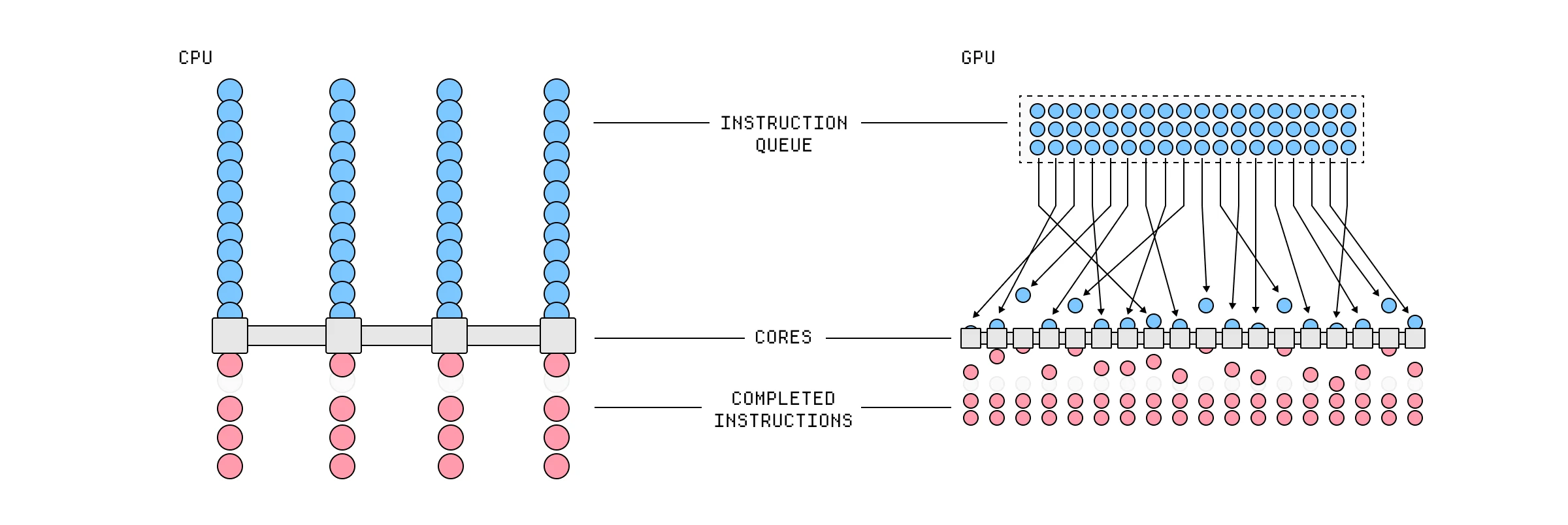
CPU 与 GPU 的指令处理管线对比。
它们做到这一点的方式是拥有数千个较小的、功能较弱的核心,这些核心非常擅长执行某些特定任务,如矩阵乘法或计算角度的正弦值。这些核心被排列成称为计算单元(Compute Units)或流式多处理器(SM)的组,可以分发任务给它们完成。
关键在于这些核心可以并行工作,因为它们擅长的操作类型很容易划分并同时完成——事实上,我们通常称这种类型的工作为“尴尬的并行”(embarrassingly parallel)。
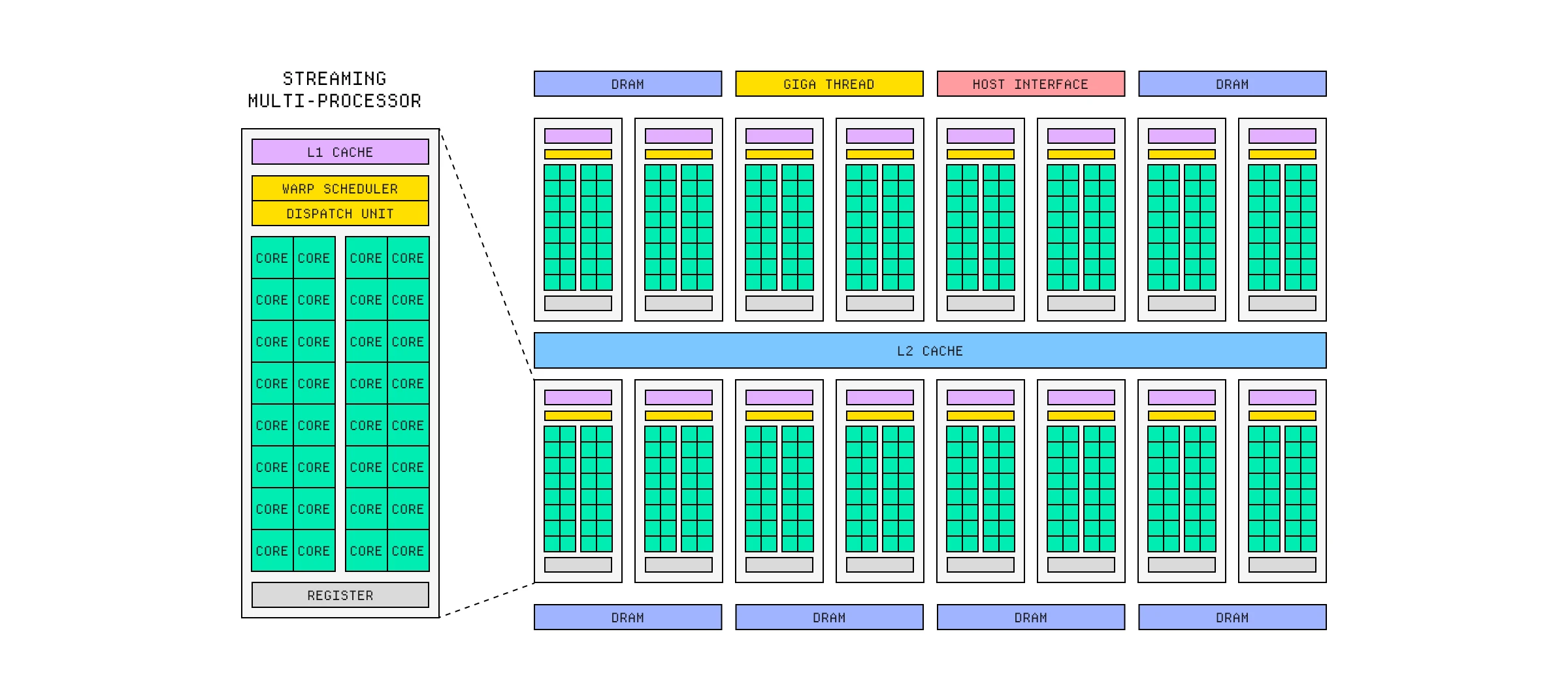
GPU 通常将核心组排列成计算单元或流式多处理器。
着色器允许我们在这些计算单元上运行程序,但你可能开始明白为什么它们有一些奇怪的限制。着色器之所以快,完全是因为它们拆分工作并相互独立运行,但这种设计必须将复杂性降至最低。
因为它们是同时运行的,一个着色器实例的计算不能依赖于另一个实例的结果。这意味着我们不能在着色器实例之间传递数据,但我们可以将数据向下传递给所有的实例。我们称这些为 Uniforms(统一变量),而不是变量,因为每个实例接收的确切值是相同的。
GPU 喜欢让所有这些核心保持忙碌,所以一旦一个核心空闲下来,就会给它分配新的工作。不能保证它的新任务与前一个任务有任何关系,所以在这个意义上,每个核心都是无记忆的,不能基于先前的输出计算某些东西。
不过并不全是并行的,不同类型的着色器作为顺序管线的一部分运行,我们可以在其中将数据从一个阶段传递到下一个阶段。让我们深入研究图形管线,看看着色器实际上是如何融入整个过程的。
图形管线 (The graphics pipeline)
着色器作为图形渲染管线的一部分运行,该管线主要设计用于渲染 3D 图形。虽然它实际上有很多步骤,但我们可以将其简化为三个主要步骤:
- 顶点着色 ↓ — 变换顶点。
- 光栅化 ↓ — 准备片段。
- 片段着色 ↓ — 计算像素值。
让我们想象一下我们在 3D 空间中渲染一个立方体,并以此为例,看看渲染该立方体时管线的每一步需要发生什么。
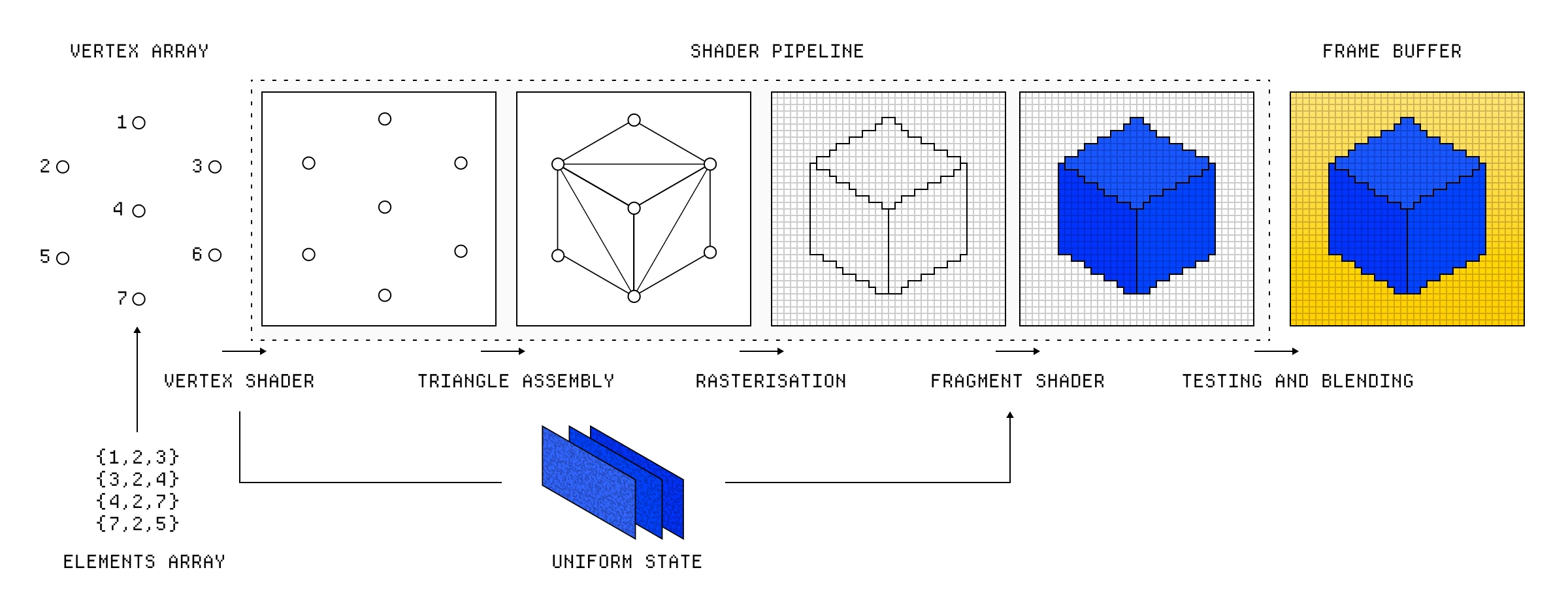
展示了不同阶段及其相互连接方式的着色器管线。
在 GPU 上发生任何事情之前,运行我们应用程序逻辑的 CPU 会向 GPU 发出一个绘制调用(draw call)。随着这个绘制调用,它将渲染场景所需的顶点数据提供给 GPU,GPU 将其作为**顶点缓冲区对象(VBOs)**存储在内存中。
顶点数据包括诸如顶点位置、任何法线、纹理坐标或渲染任何给定几何体所需的材质属性之类的东西。
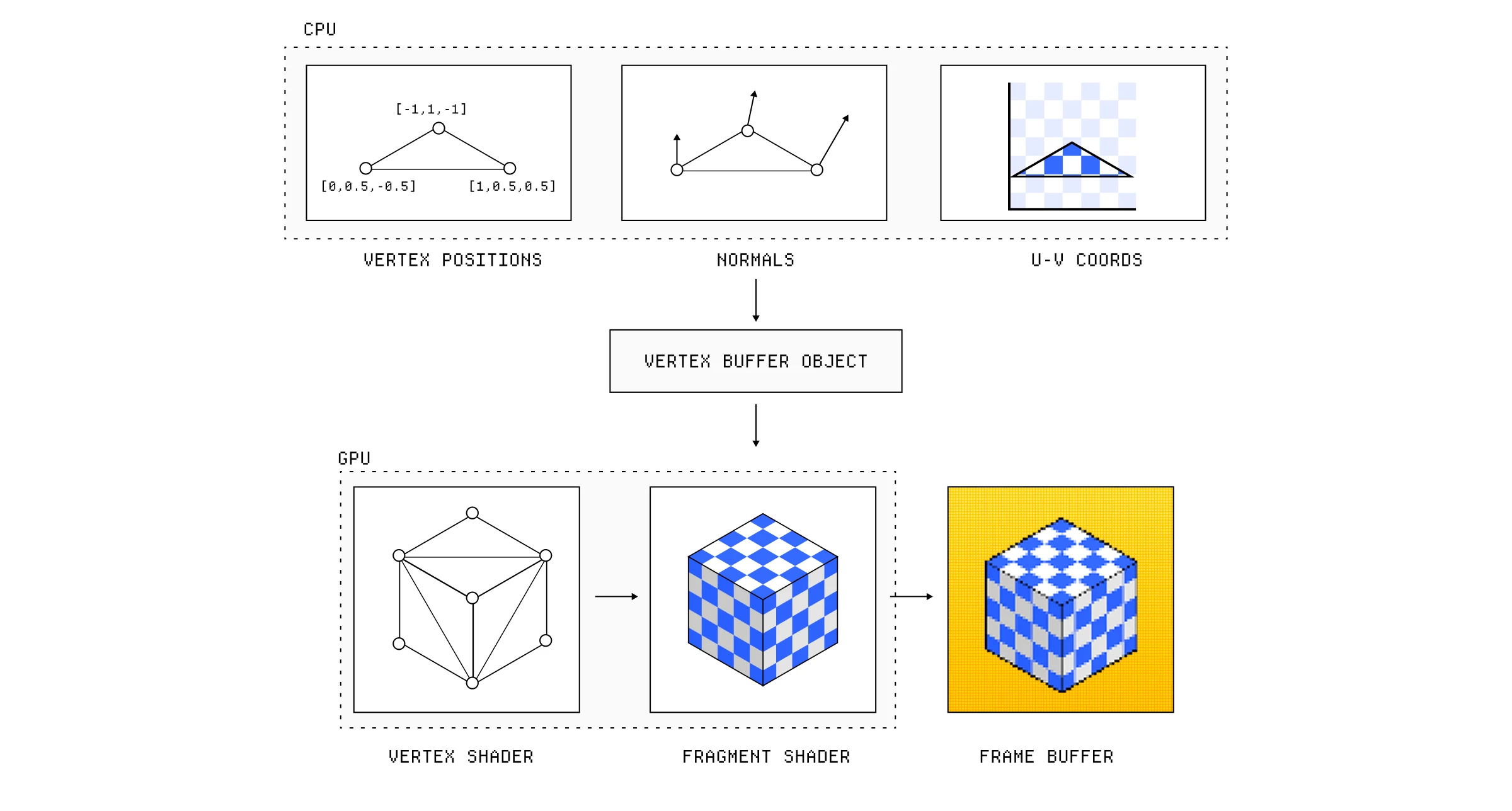
CPU 为图形管线准备数据。
在 GPU 上发生的第一个步骤是输入装配器(Input Assembler, IA)。它从 VBO 读取顶点数据,并开始使用这些数据组装图元(primitives)。在我们的例子中,它将获取顶点数据并用三角形构建立方体。
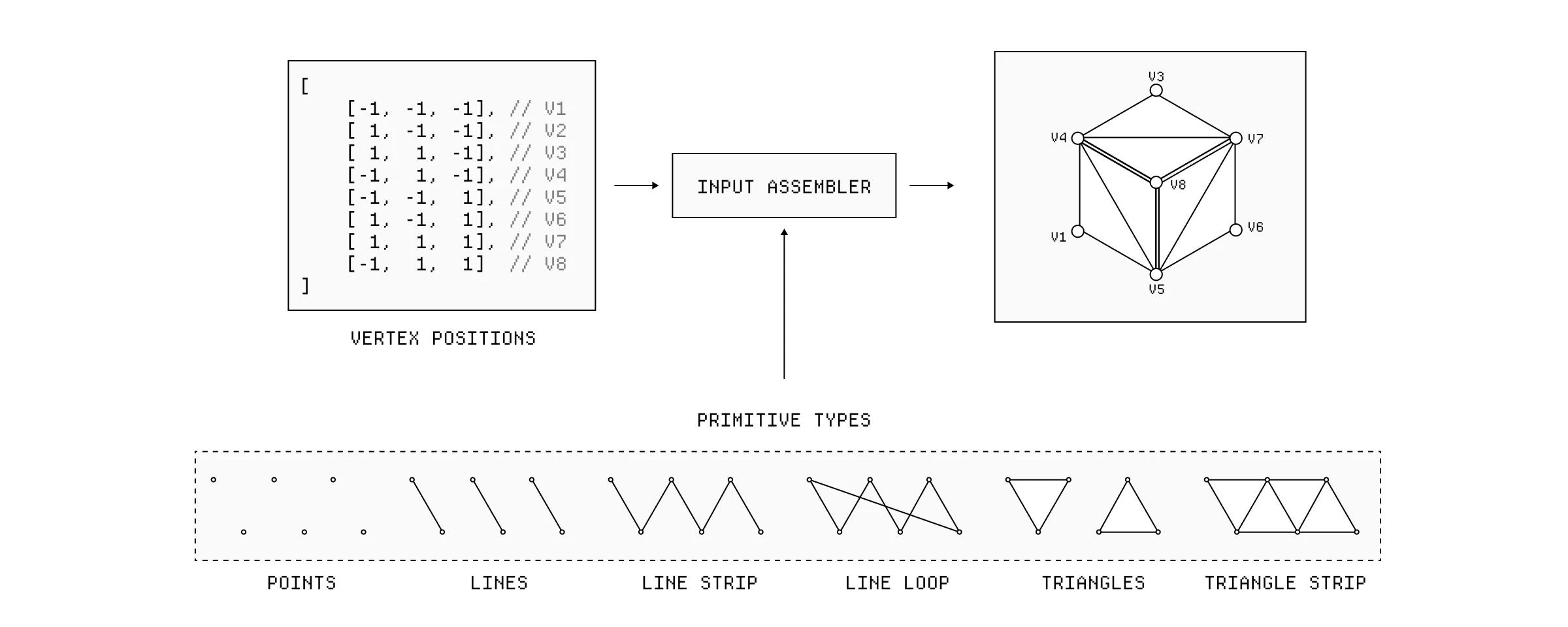
输入装配器获取顶点数据并将其组装成图元。
这很重要,因为现在我们确切地知道我们的形状将有多少个顶点,以及我们需要运行多少个顶点着色器实例。
顶点着色 (Vertex Shading)
顶点着色器为几何体中的每个顶点运行一次,因此很明显,着色器的每个实例运行时,顶点的位置值都是不同的。由于顶点着色器决定了顶点在最终场景中的位置,我们可以使用它来任意变换该位置。
要旋转立方体,我们可以将旋转矩阵应用于每个顶点,其中角度基于经过的时间。请记住,旋转矩阵是一个 uniform,这意味着它对于每个顶点都是相同的,只有顶点位置对于我们着色器的每个实例是不同的。
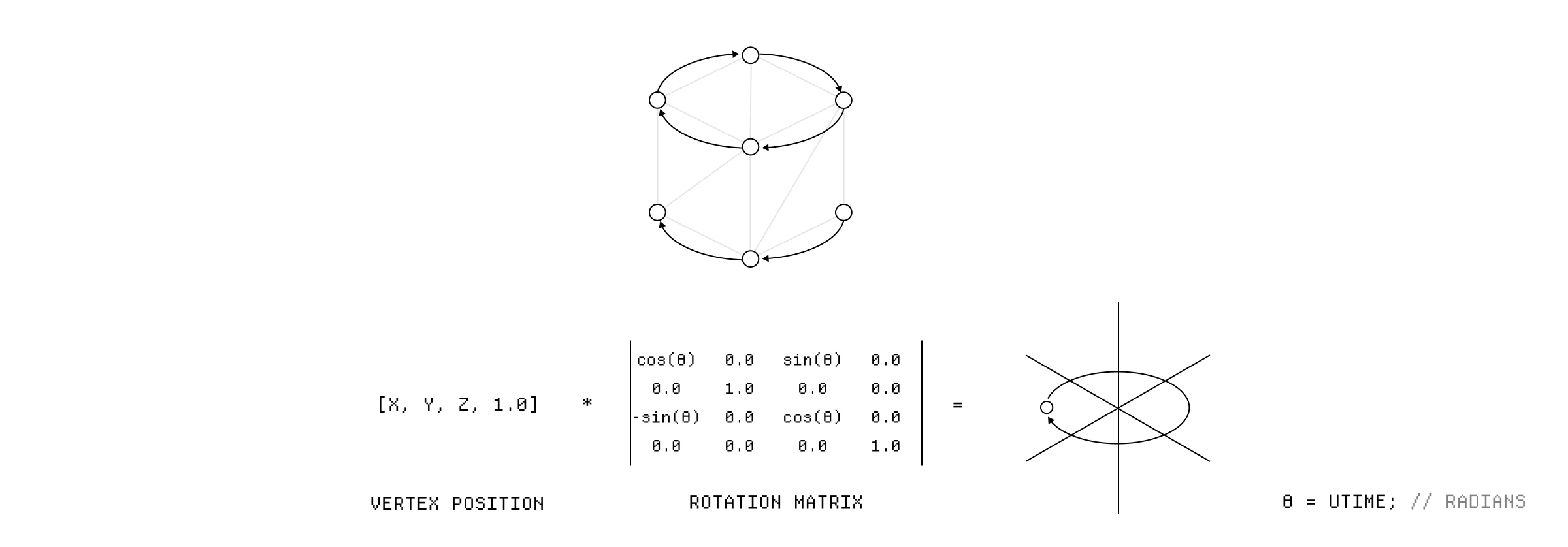
应用旋转矩阵来旋转立方体的顶点。
这还是一个相当简单的例子,但顶点操作允许你应用以此之外很难实现的效果。想象我们有一个平面,它由网格中的数十个顶点组成。仅使用一些基本的三角函数,我们就可以用正弦波操纵平面的每个顶点。
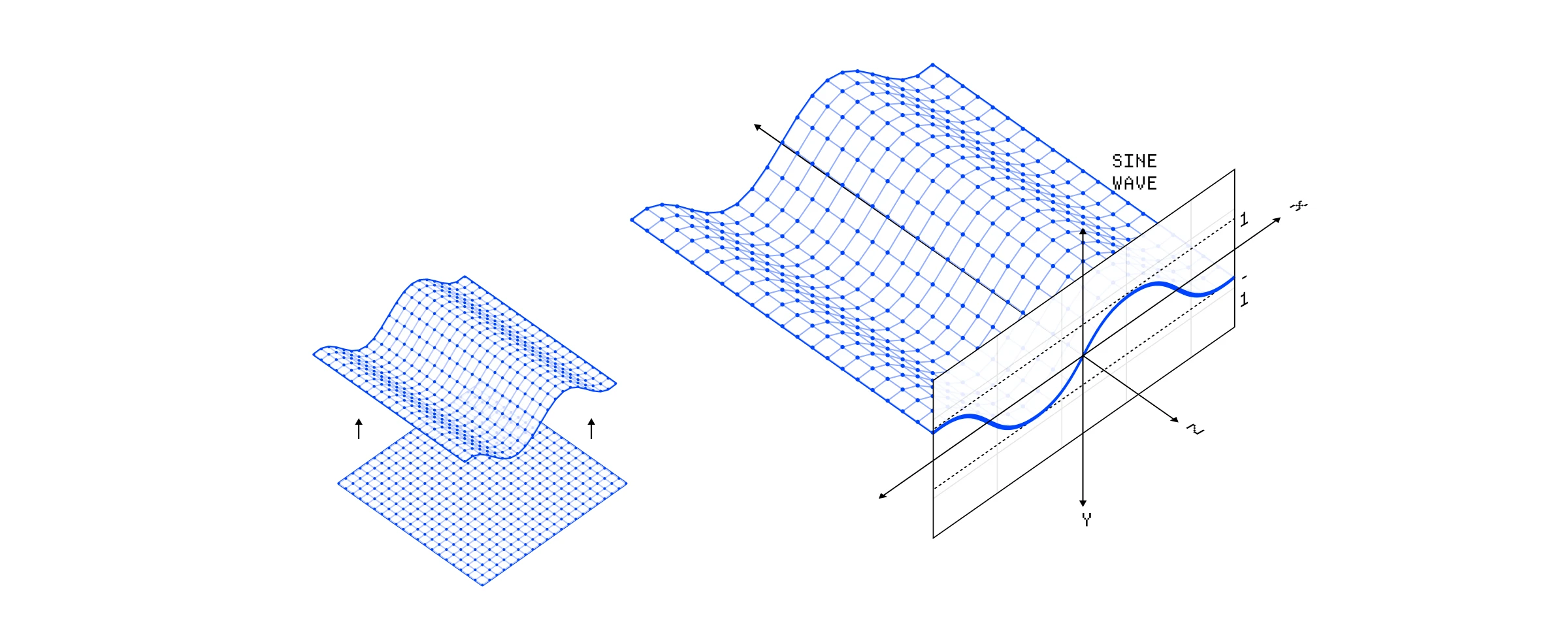
一个将正弦波应用于平面的顶点着色器。
现在我们在一个方向上应用正弦波,但如果我们从原点应用它,我们可以创建一个涟漪。
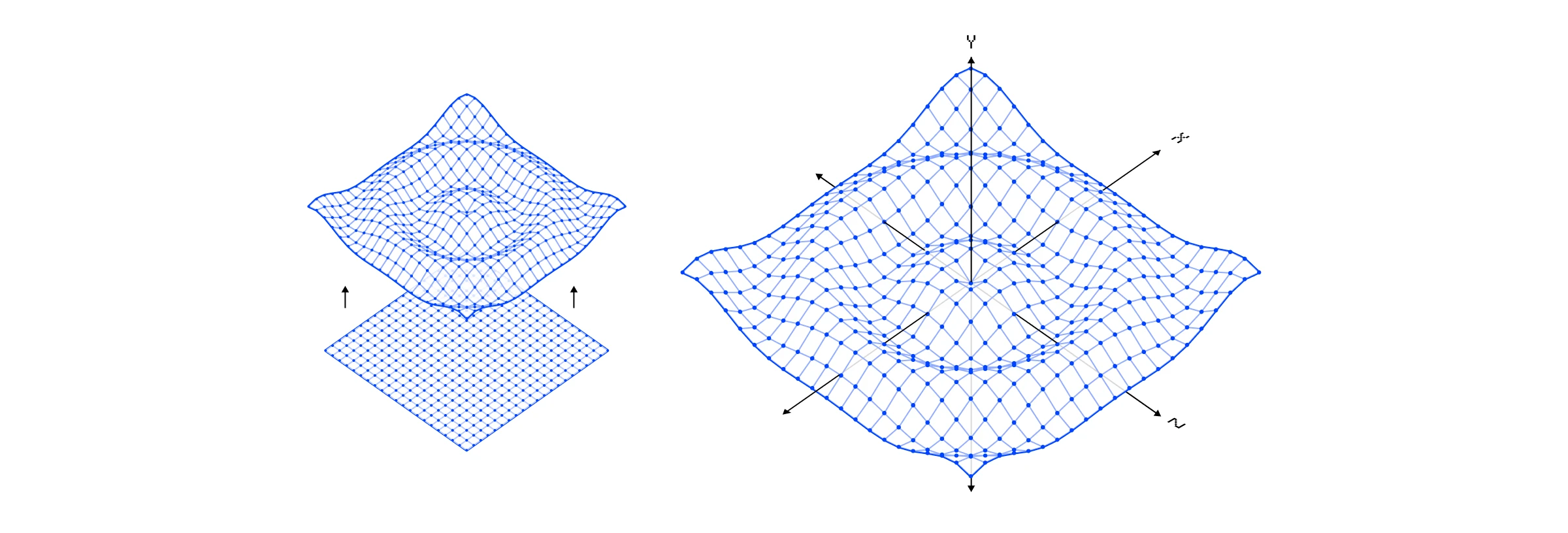
一个将涟漪波应用于平面的顶点着色器。
我们可以使用一些 uniforms 将参数传递给我们的顶点着色器——在这种情况下,我们正在改变正弦波的频率和振幅。虽然 uniforms 对于着色器的每个实例都是相同的,但我们可以随时间更新 uniform,以便每一帧都获得新值。
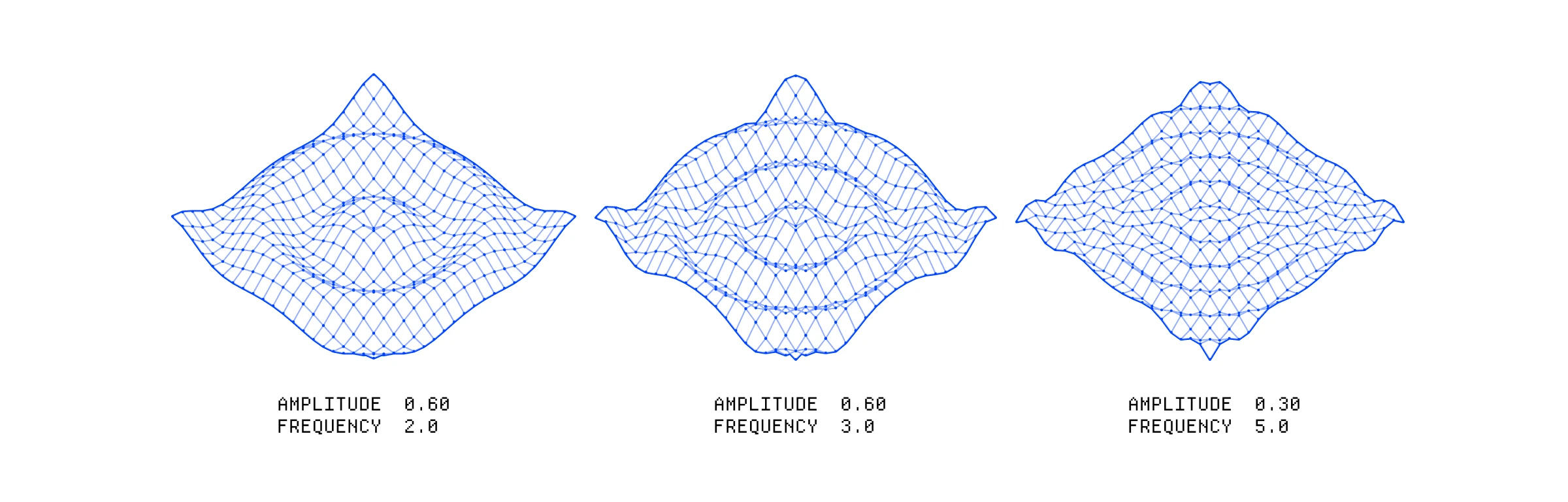
三个不同的平面,展示了正弦波频率和振幅调制的效果。
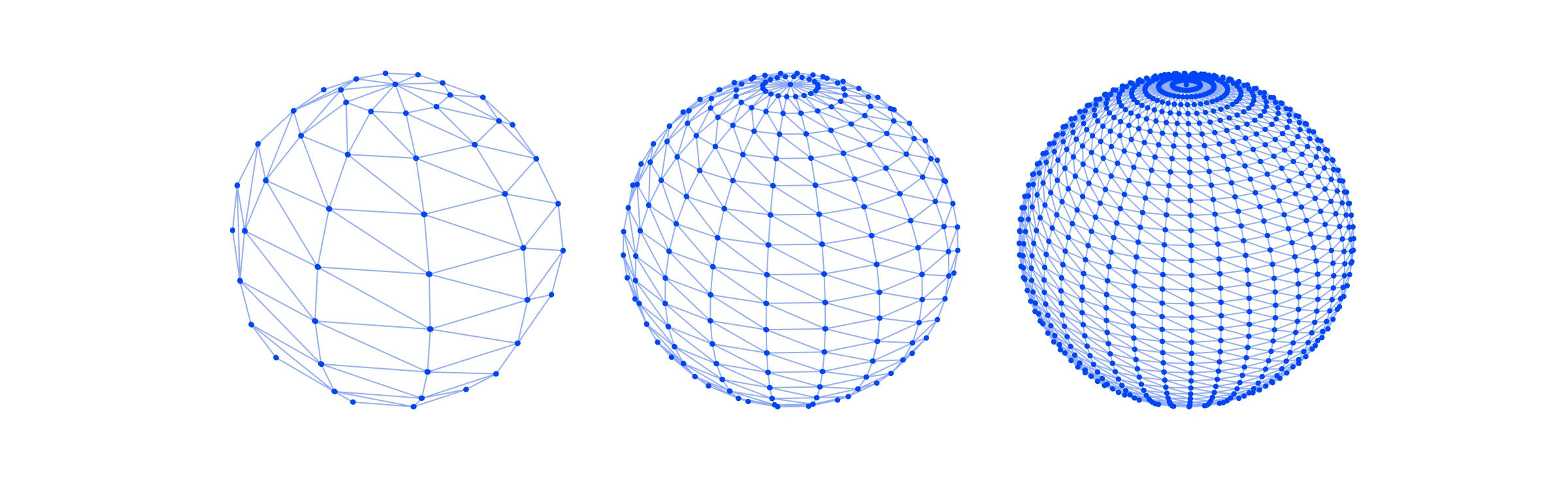
我们可以决定给定网格有多少个顶点——在 3D 软件中,我们通常可以为像这样的基本形状设置细分。更多的细分意味着更多的交叉点,因此有更多的顶点。我们可以根据想要显示的细节量来做出选择,但这伴随着性能权衡。
顶点着色器需要为每个顶点运行,因此将顶点数量加倍显然会使顶点着色器的运行次数和所需的线程数量加倍。
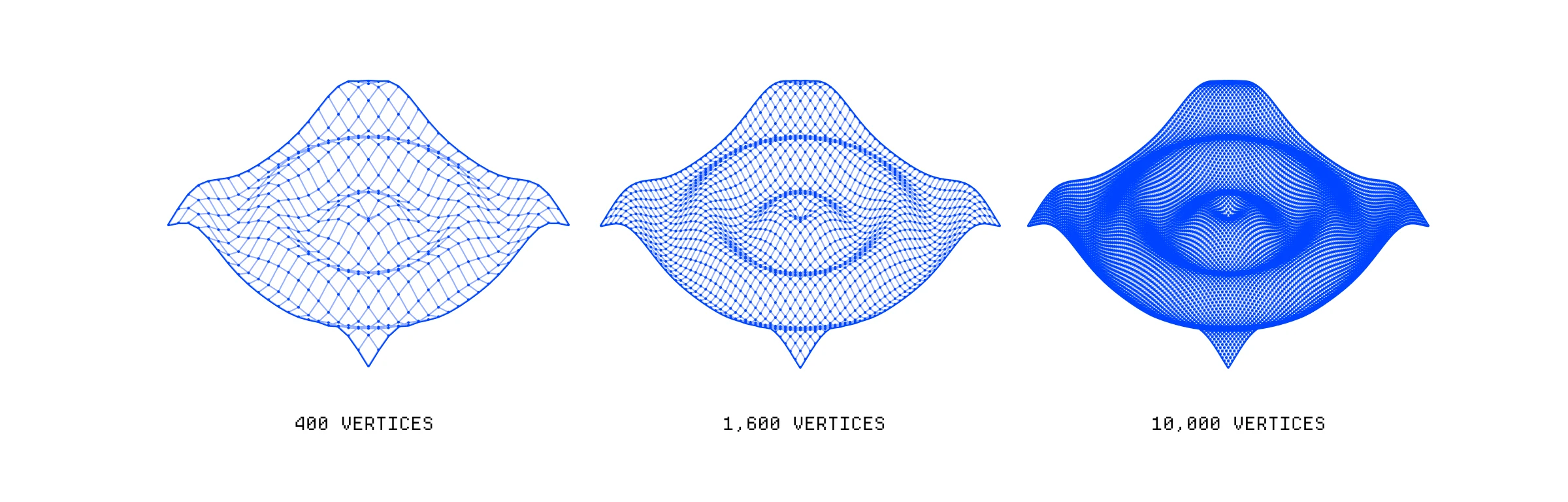
三个不同的平面,展示了增加平面网格中顶点数量的效果。
在我们的顶点着色器返回顶点信息之前,我们通常需要将其转换为屏幕空间(Screen Space)。如果你曾经使用过 3D 程序,你会知道当你创建一个几何体时,它有一个原点,即每个轴开始的点 { x:0, y:0, z:0 }。对于我们的立方体,原点在其中心,因此给定顶点的坐标是相对于这个原点的。
但是显然,当我们实际上想要渲染这些几何体时,我们需要它们相对于平面屏幕的坐标。为此,第一步是将坐标从模型空间(Model Space)转换到世界空间(World Space)。我们通过将每个顶点乘以 modelMatrix 来做到这一点,这是一个从 3D 应用程序传递给着色器的矩阵 uniform,使坐标相对于世界原点。
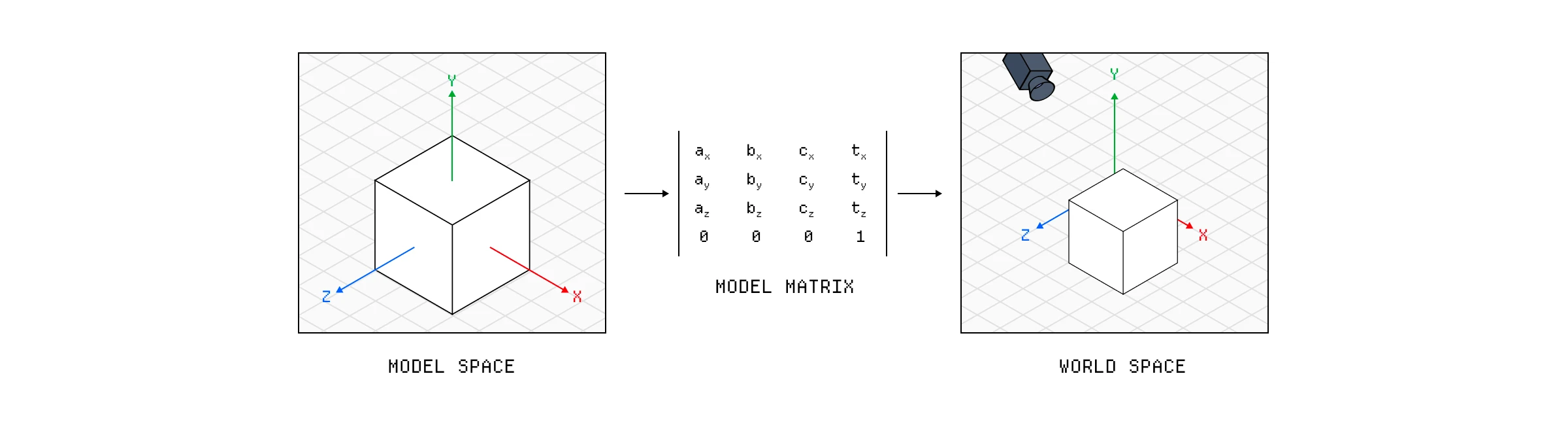
从模型空间转换到世界空间的过程。
模型矩阵实际上是我们通常应用所有基本变换(如我们目前描述的旋转、缩放和平移)的地方。我们实际上从未更新原始顶点位置,而是在此矩阵中描述它们的变换。
接下来,我们需要弄清楚顶点相对于相机的位置,称为视图空间(View Space),我们通过将顶点数据乘以 viewMatrix 来实现。最后,我们使用 perspectiveMatrix 应用相机透视,并将坐标相对于视口大小和分辨率进行变换。
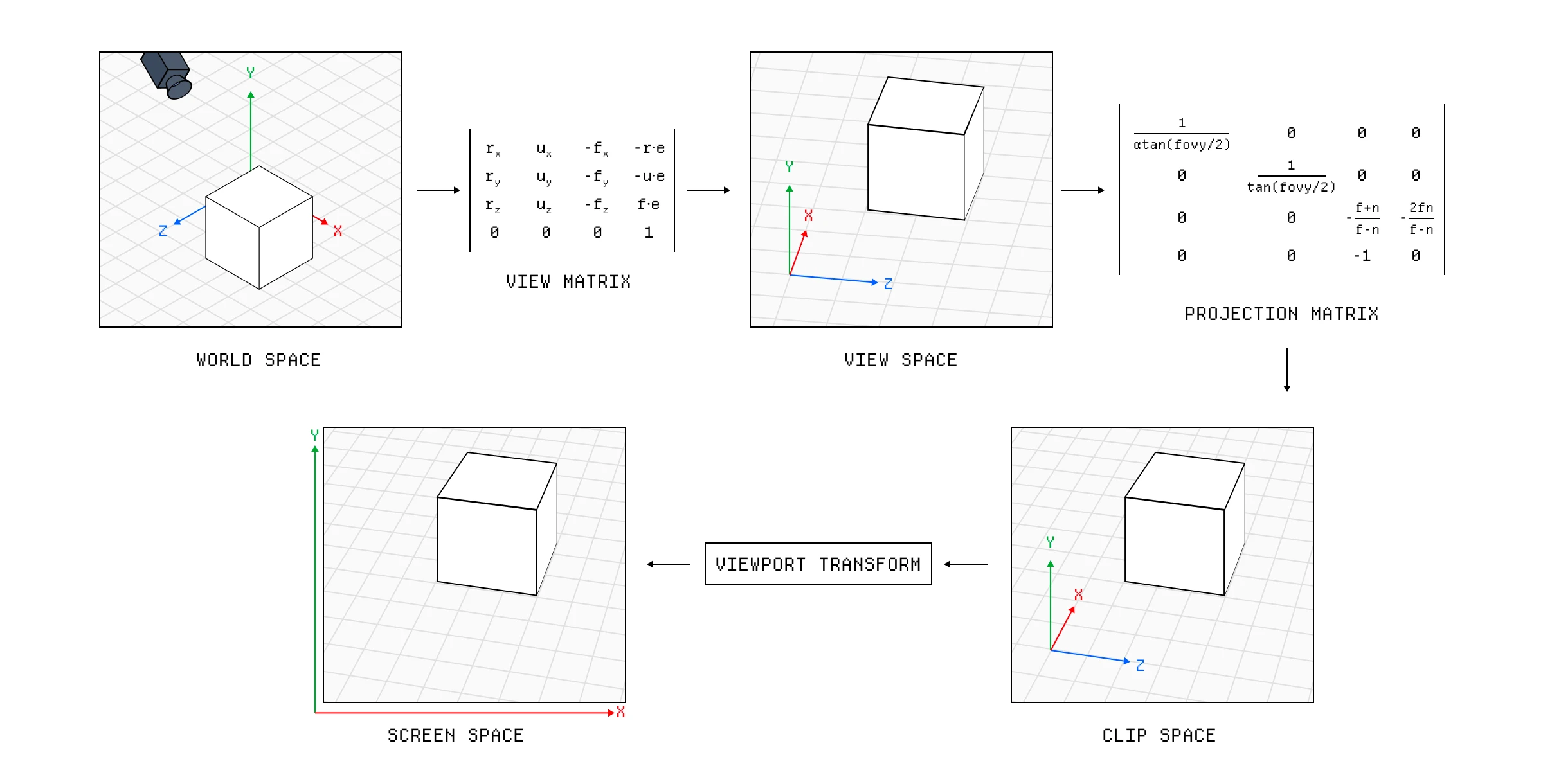
从世界空间转换到屏幕空间的过程。
在我们进入下一步之前,还记得我们说过着色器不能真正相互通信吗?嗯,这不完全正确。因为顶点着色器在片段着色器之前运行,我们可以将顶点着色器中计算的变量传递给片段着色器。这些在历史上被称为 Varyings(易变变量),因为与 uniforms 不同,它们将根据顶点着色器的输出而有所不同。
例如,假设我们要让每个顶点有不同的颜色,所以我们要从顶点着色器返回一个名为 vColor 的 varying。当那个颜色值被传递给片段着色器时,它会被插值(interpolated),所以如果我们的片段碰巧位于蓝色和红色顶点的一半位置,它接收到的 vColor 值将是紫色的。
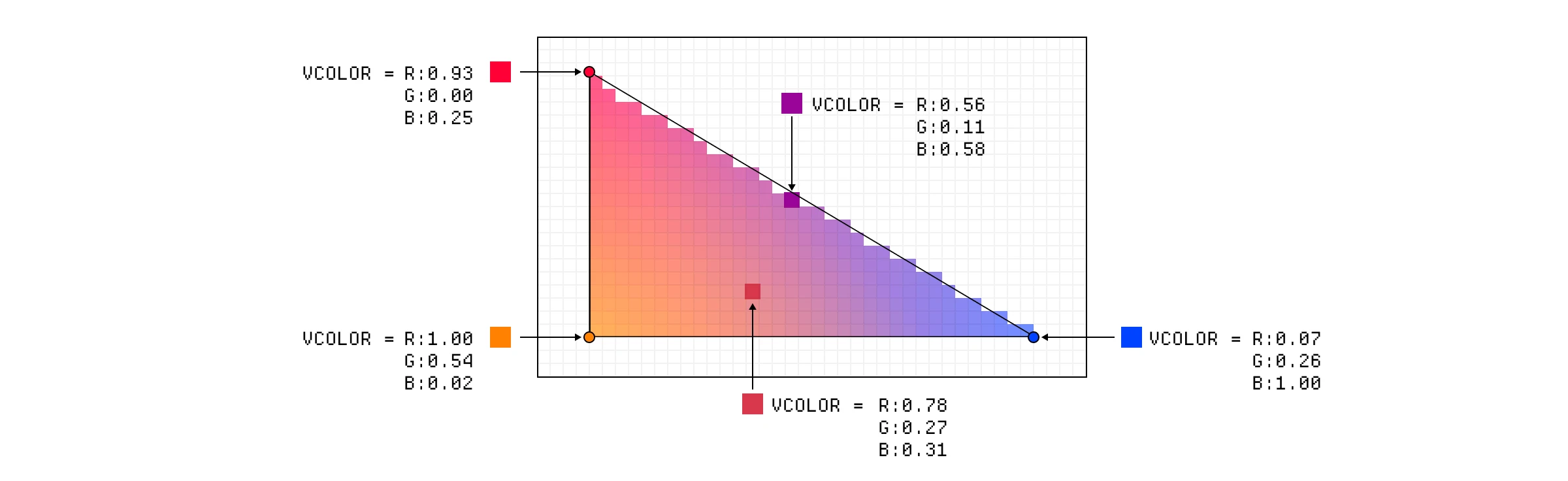
易变变量如何在片段之间进行插值。
这也是我们将法线(基本上是描述表面朝向的向量)传递给片段着色器以进行光照效果的方式。
在现代图形系统中,顶点着色器之后和光栅化器之前实际上还有几个可选步骤:曲面细分和几何着色器。我不想让你太困惑,所以我们不会在这里深入探讨这些细节。
曲面细分着色器基本上允许我们通过将几何体细分为更小的图元来增加几何体的细节。你可能会在视频游戏中使用它来增加离相机更近的物体的细节。对我们的玩具示例来说不是特别有帮助。
曲面细分着色器可以动态地向几何体添加更多细节。
几何着色器允许我们完全动态地添加或删除元素。所以,也许我们确定一个元素离相机太远以至于不应该被渲染,我们可以使用几何着色器来做到这一点。
光栅化 (Rasterisation)
这就是我们必须从点和坐标转变为像素的地方。光栅化器是一个不可编程的步骤,它获取图元及其变换后的位置,并弄清楚它们覆盖了哪些像素,这就是我们需要将坐标转换为屏幕空间的原因。
你可能已经注意到我们的立方体实际上是由三角形组成的,每个光栅化器在单个三角形上工作,以弄清楚哪些像素落在其中。对于这些像素中的每一个,它都会生成一个片段(Fragment)。
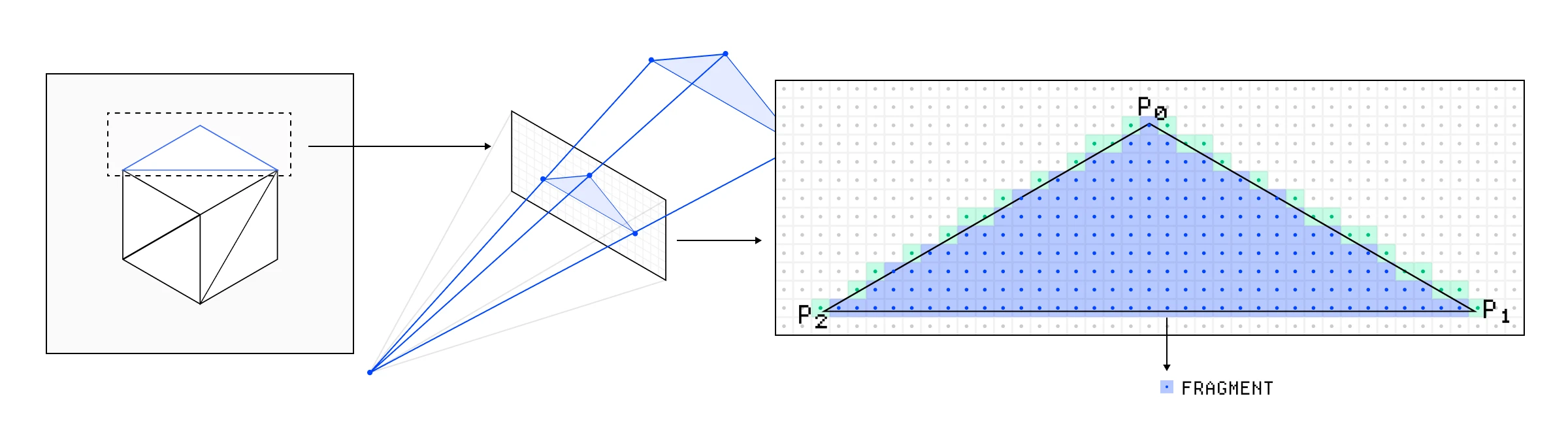
光栅化器根据三角形覆盖的像素生成片段。
片段基本上是我们的片段着色器弄清楚像素最终颜色所需的所有信息——这包括任何 uniforms、纹理和从顶点阶段插值的 varyings,以及该点形状的深度。
我们在这里稍微超前了一点,但每个片段的深度对于所谓的深度测试很重要。其想法是,如果这个片段因为落在遮挡它的东西后面而不可见,我们就不应该费心将其写入帧缓冲区。
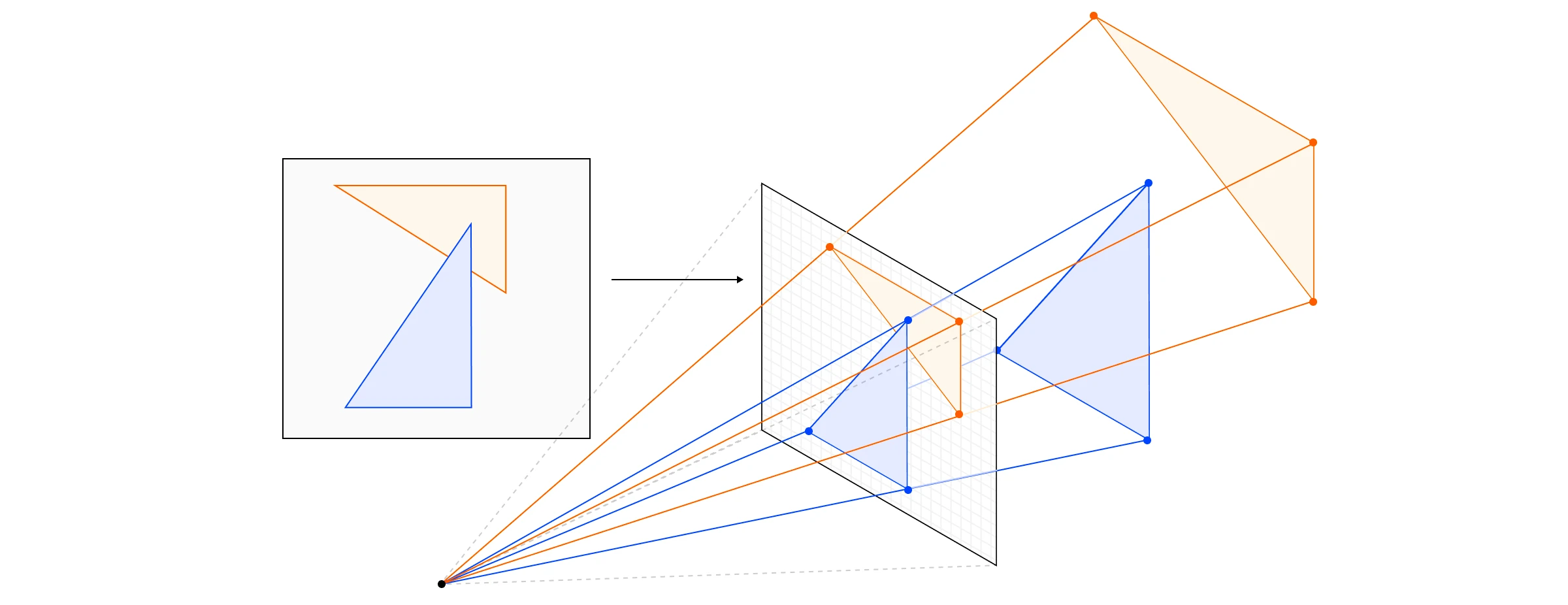
深度测试检查哪些形状相互遮挡。
在实践中,这意味着当我们去将片段写入帧缓冲区中的特定像素坐标时,我们检查 Z-buffer(深度缓冲区)中该像素的深度值,并且只有当我们的片段值小于那个值时才覆盖它。
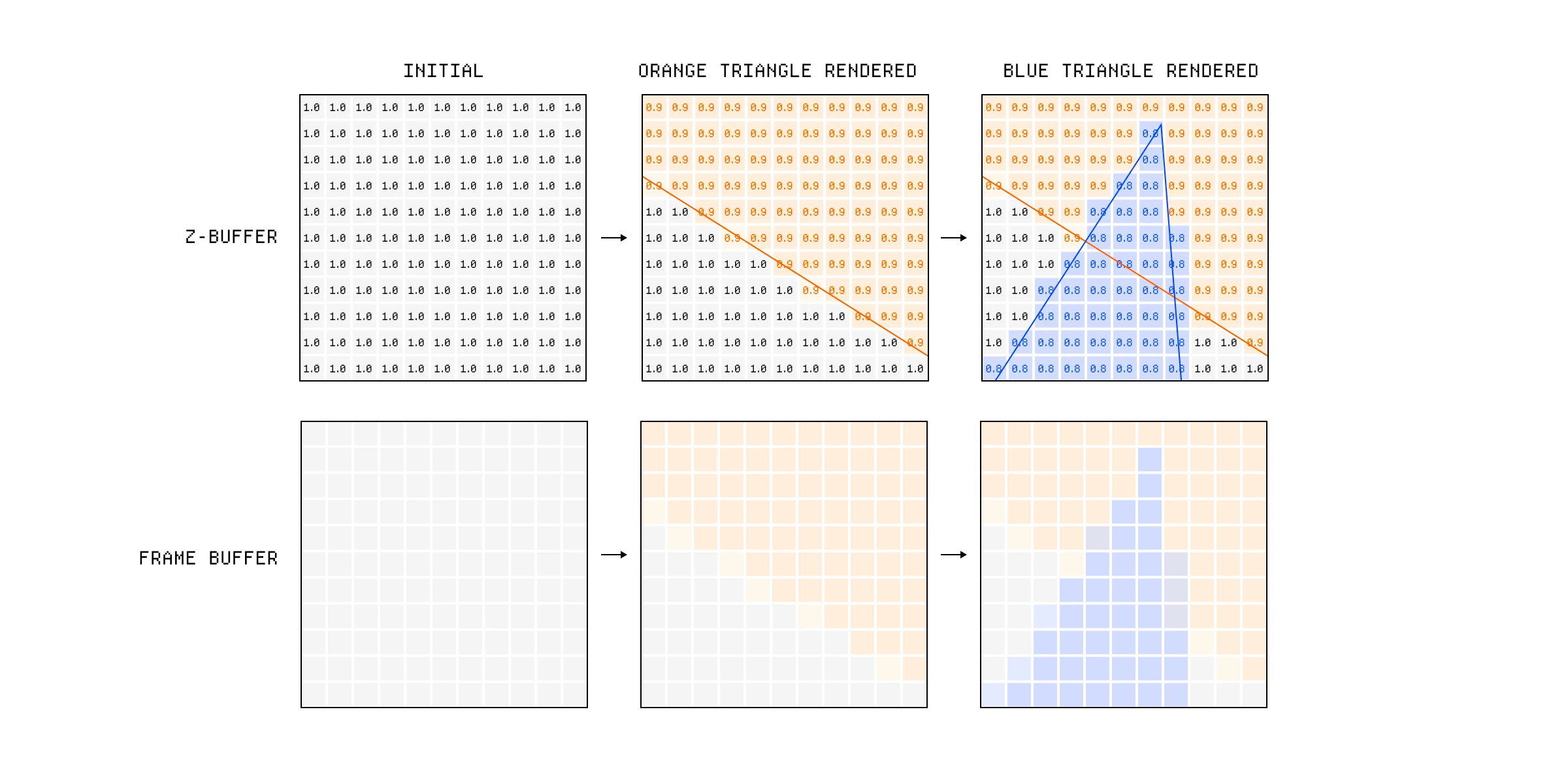
帧缓冲区仅根据深度缓冲区中的值进行更新。
在这里发生的另一件复杂的事情是抗锯齿。因为我们正在从矢量坐标转换为像素网格,所以会有一些像素被三角形半覆盖。理想情况下,我们希望这些片段成为一种基于覆盖它的两个形状的混合颜色。
为此,现代系统使用多重采样抗锯齿(MSAA),它在这些边缘像素内采样多个点,以确定每种颜色混合多少。我们使用片段覆盖的采样点数量来弄清楚当我们最终写入帧缓冲区时如何加权两种颜色的混合。
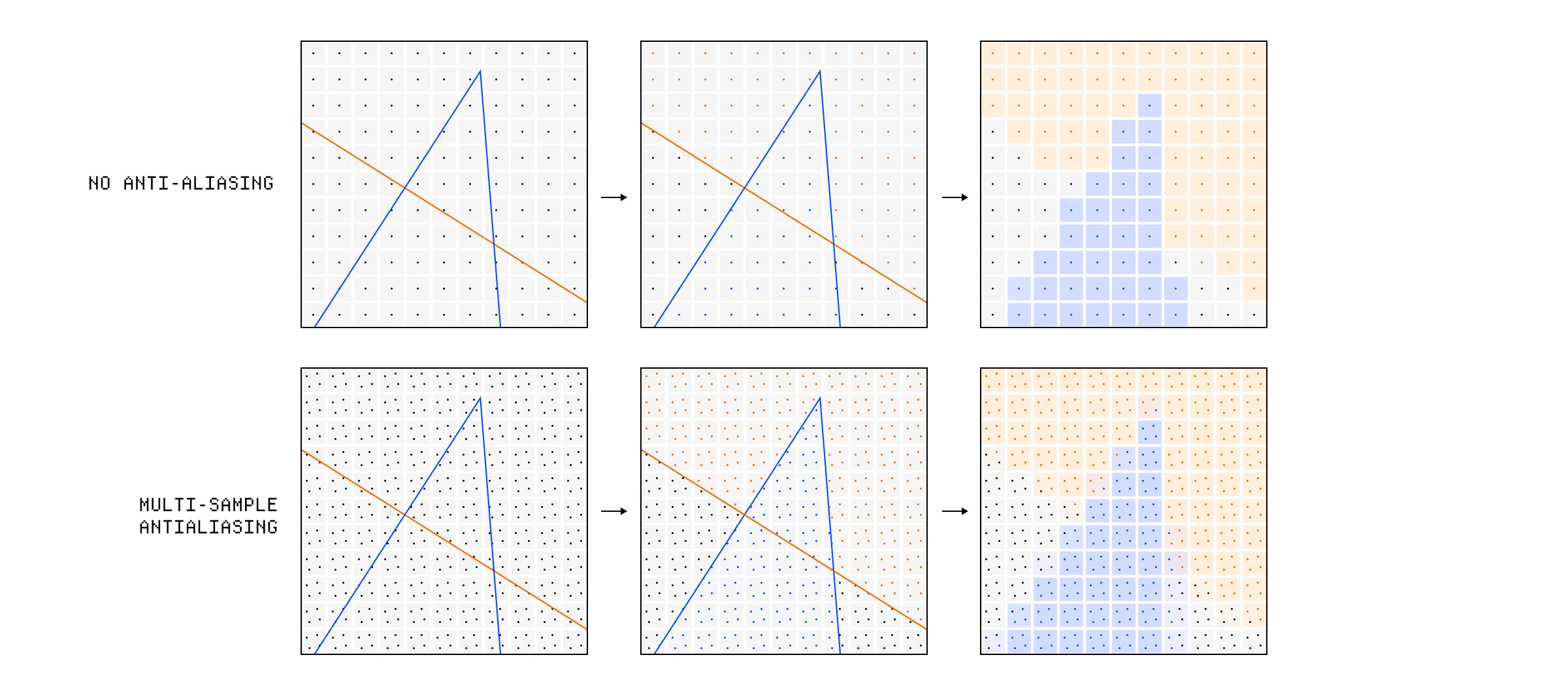
多重采样抗锯齿用于混合掉锯齿伪影。
很复杂,我知道。无论如何,在光栅化器生成片段后,我们为每一个片段启动一个片段着色器并发送片段数据。
片段着色 (Fragment Shading)
所有这些信息显然都被传递给片段着色器,片段着色器将使用它来确定被此片段覆盖的像素的颜色值。在最简单的情况下,片段着色器只是应用纹理、光照模型和其他材质属性。
让我们通过一个简单的例子来看看如何使用片段着色器创建渐变。为了简单起见,想象一下,我们只是在一个 20 像素高和 20 像素宽的平面上工作。这个平面上的 400 个像素中的每一个都是一个片段,它们都由同一个片段着色器决定。
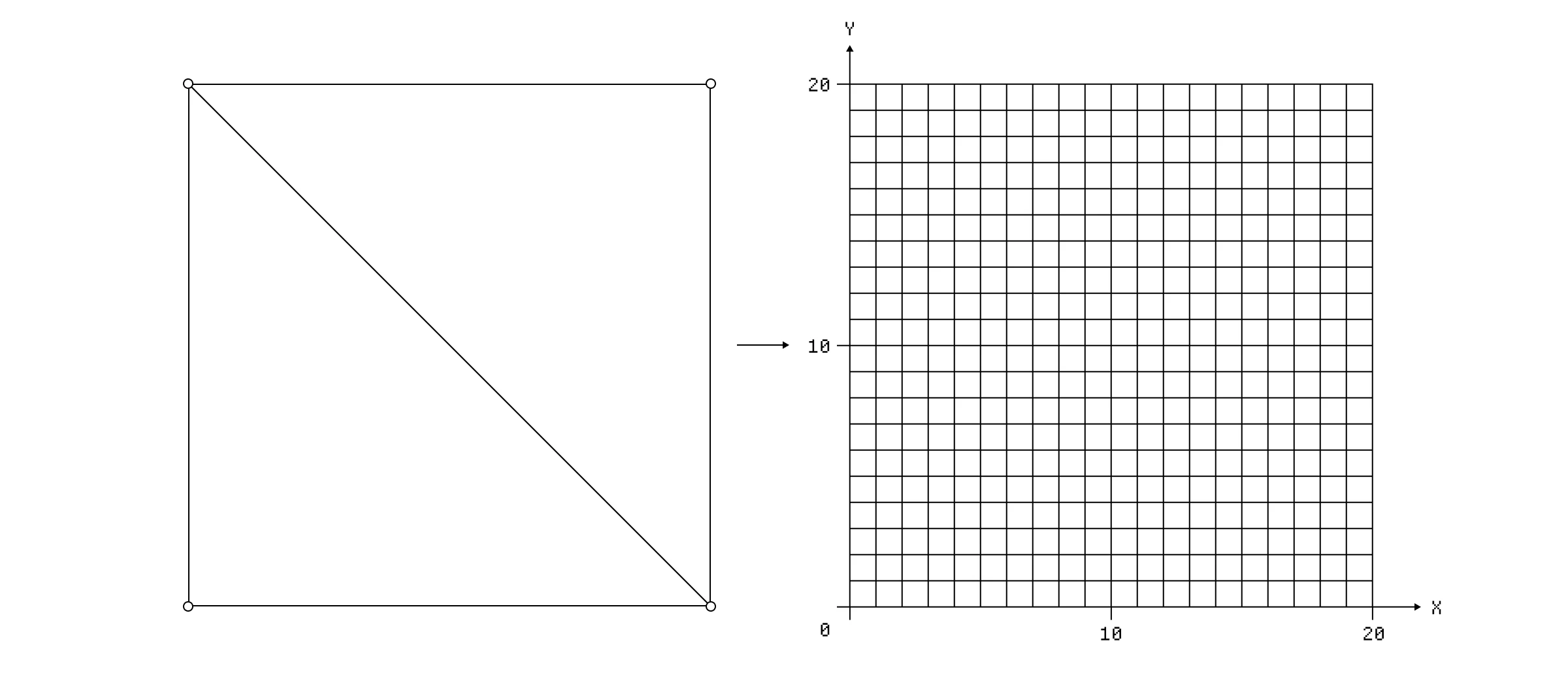
一个简单的 20 x 20 平面,包含 400 个独立的片段。
一个片段着色器有一个单一的 main() 函数,它返回一个颜色值。如果我们只是希望整个平面是相同的颜色,那很简单,我们只需确保我们的片段着色器返回该颜色。
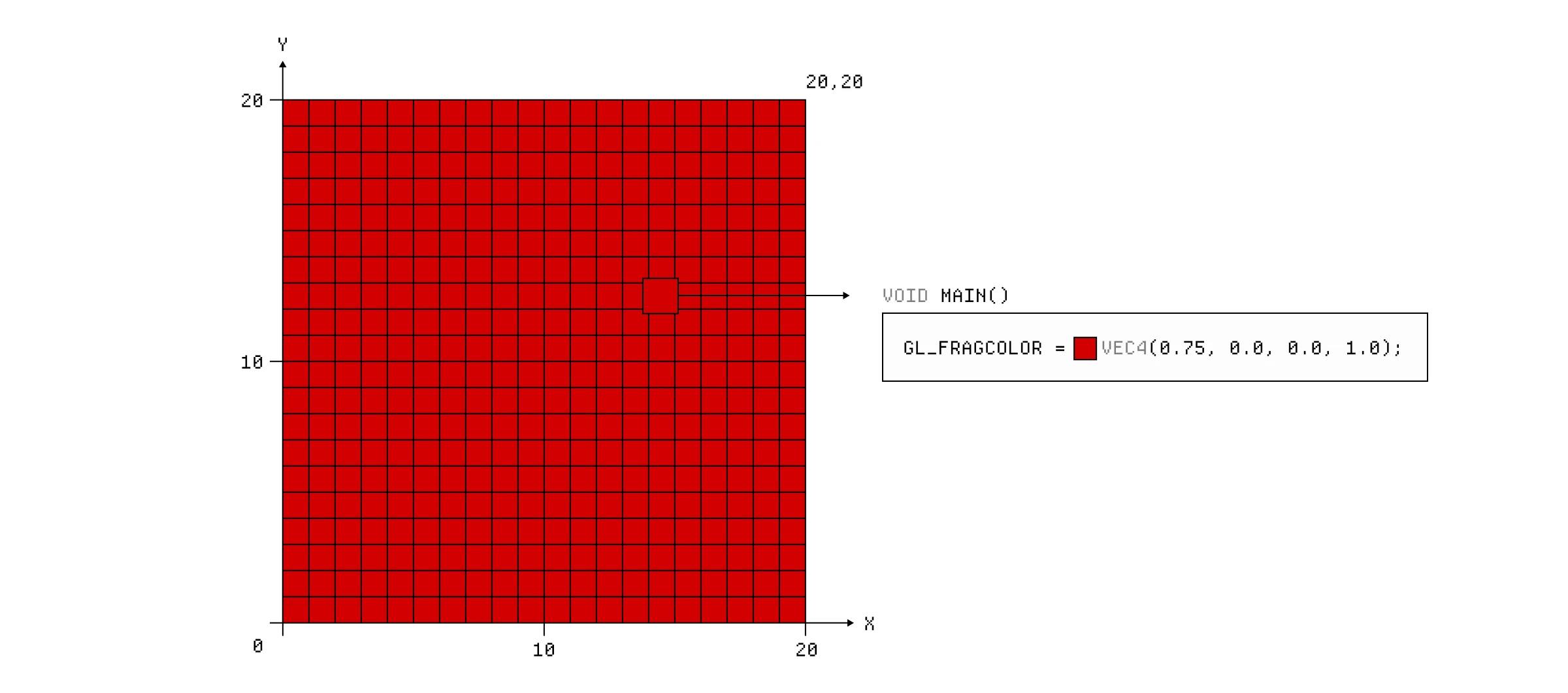
一个简单的片段着色器,为每个片段返回单一颜色 rgb(0.75,0.0,0.0)。
但是,当我们的着色器真正知道的只是它正在计算的像素的 x 和 y 坐标时,我们如何应用像渐变这样的东西呢?好吧,记得我们可以向我们的片段着色器的每个实例传递一些 uniforms,比如宽度和高度。
我们可以将分辨率存储在一个 vec2 uniform 中,这是一个具有 2 个分量(宽度和高度)的向量。为了制作一个从左到右的简单渐变,我们可以将片段位置(也是一个 vec2)除以分辨率,并使用结果的 x 分量作为最终颜色的红色分量。
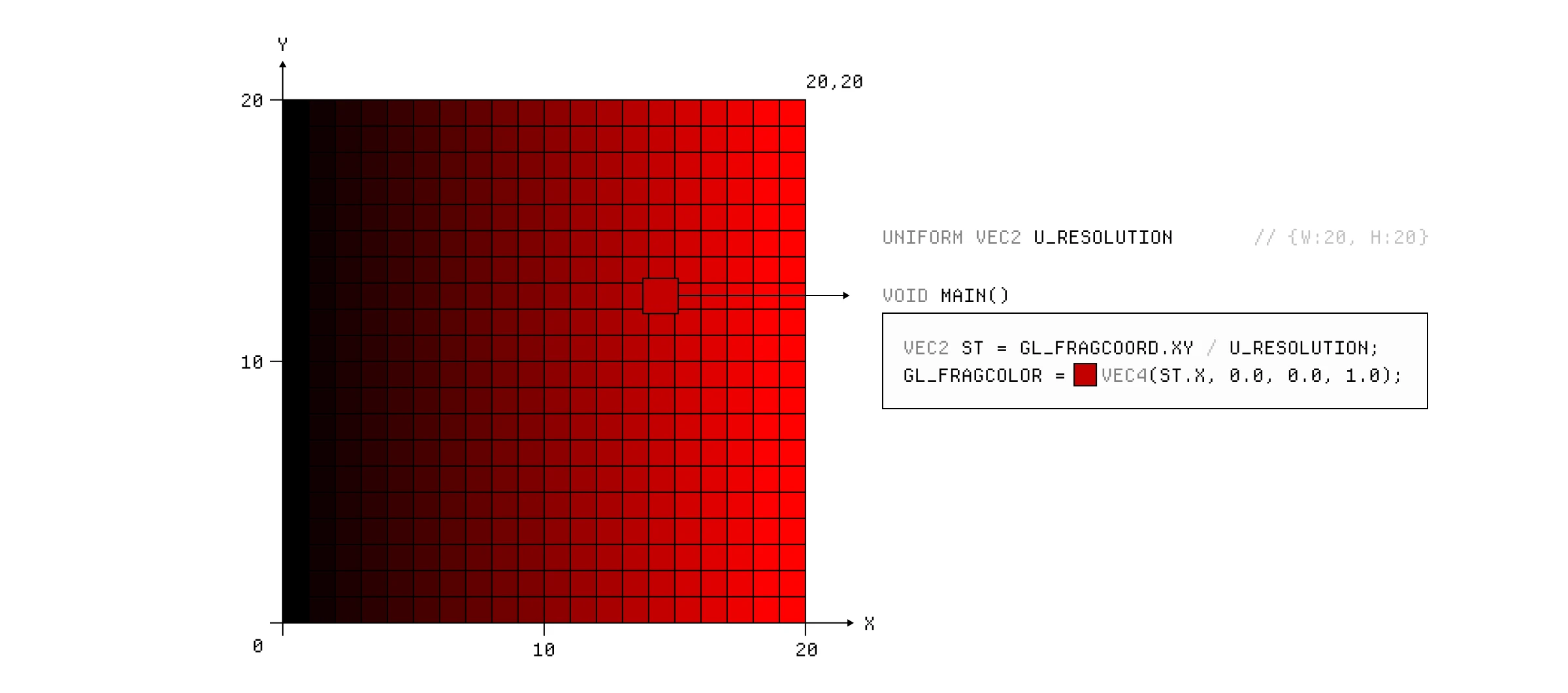
一个简单的片段着色器,返回 X 轴上的渐变。
如果我们想要垂直渐变,我们可以改为返回向量的 y 分量。
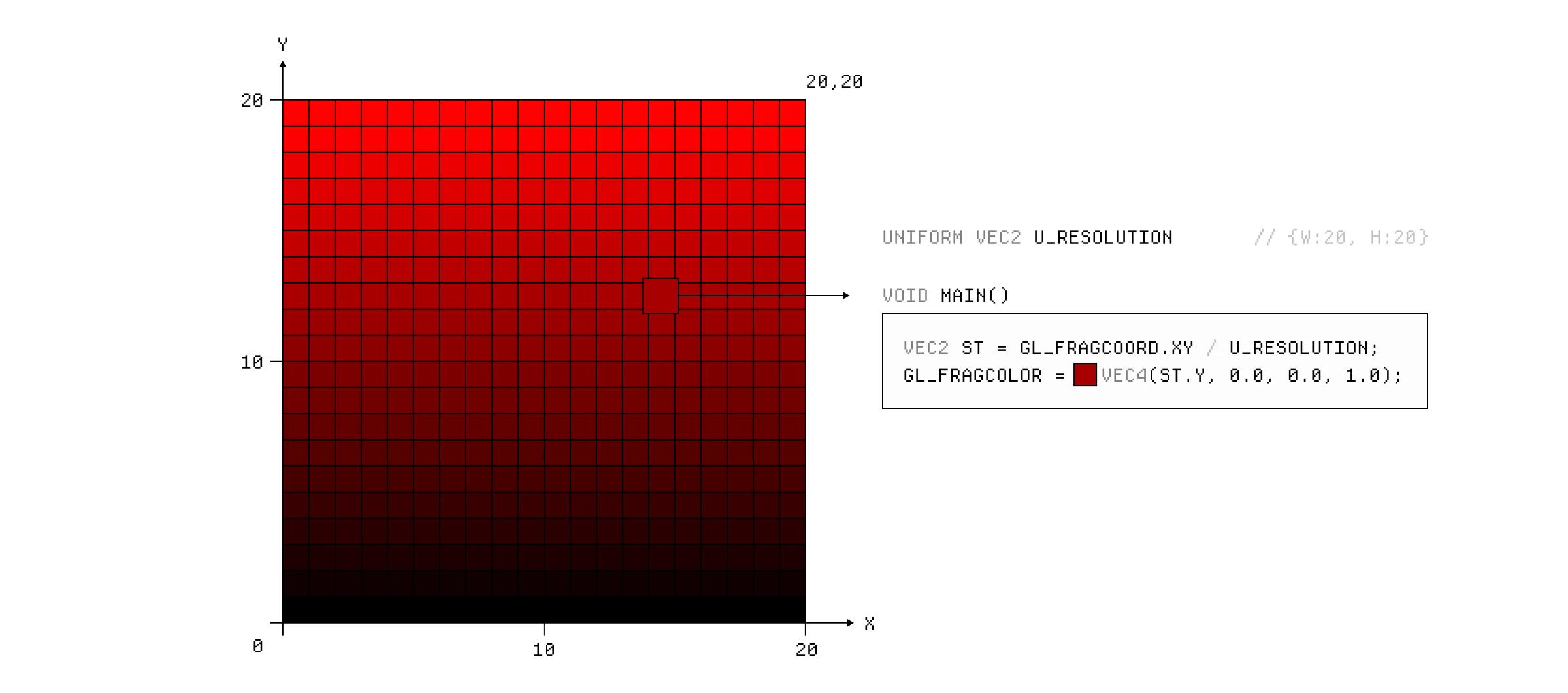
一个简单的片段着色器,返回 Y 轴上的渐变。
我们可以通过在最终颜色分量中使用 st 向量的不同分量来玩转这个渐变的各种变化。
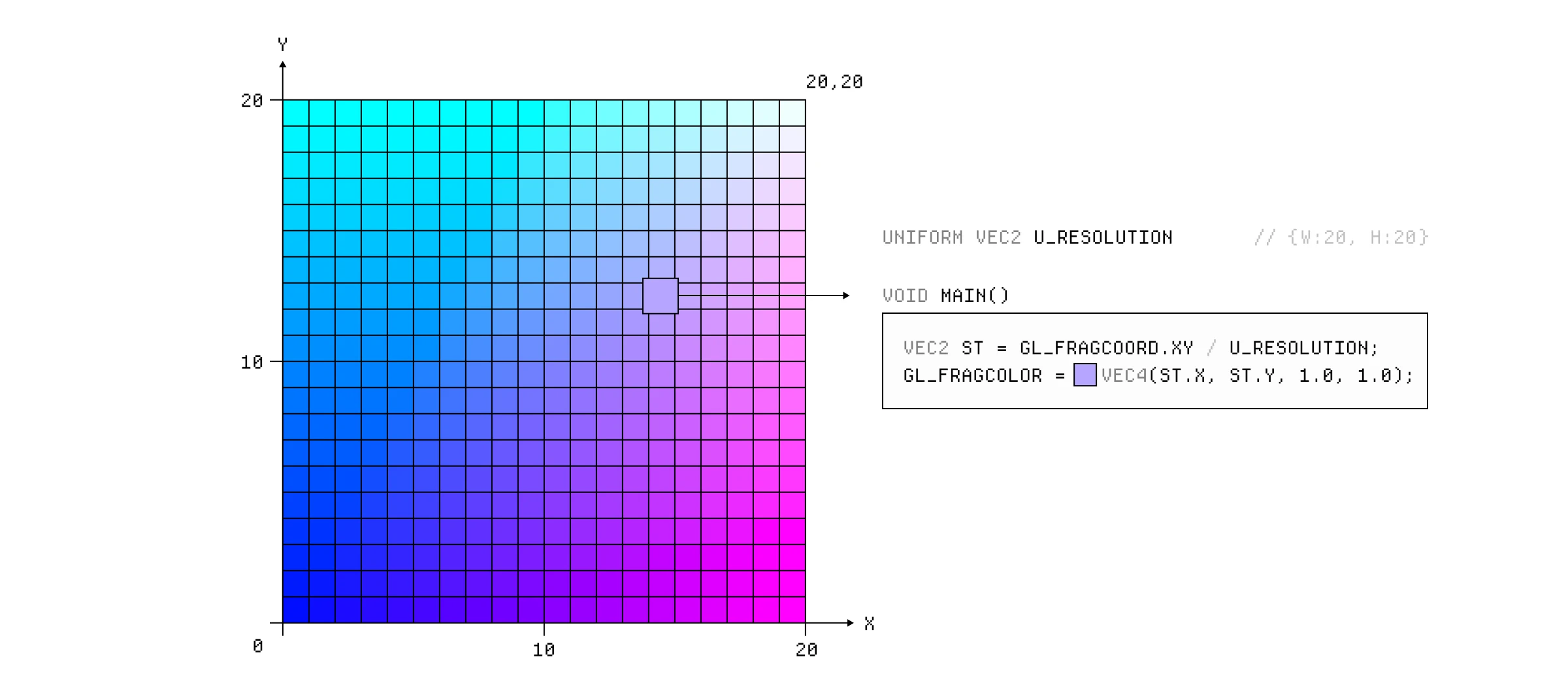
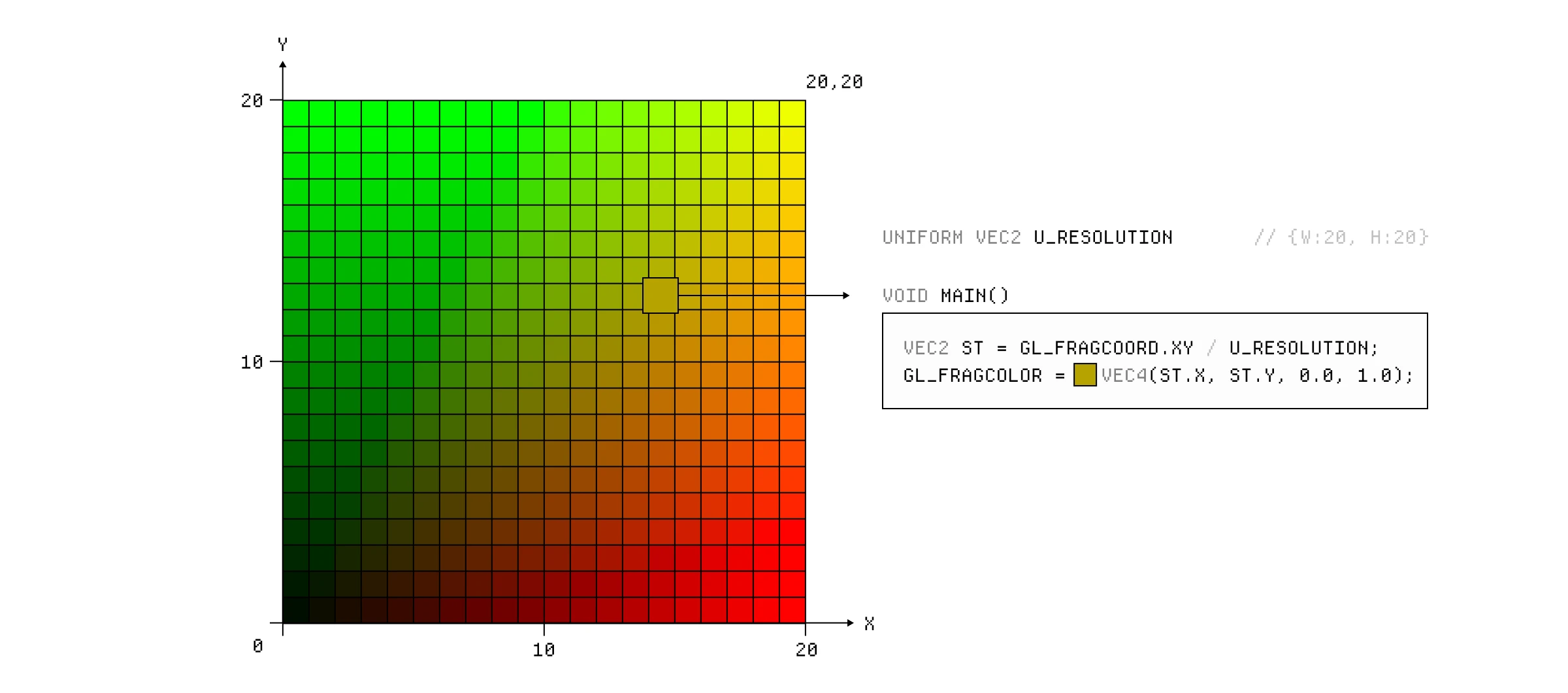
我们还可以使用当前时钟时间和一些三角函数来随时间动画化颜色分量。请记住,每一帧都会获得 u_time uniform 的新值,这与 sin() 函数结合会导致绿色分量在 1 和 -1 之间振荡。
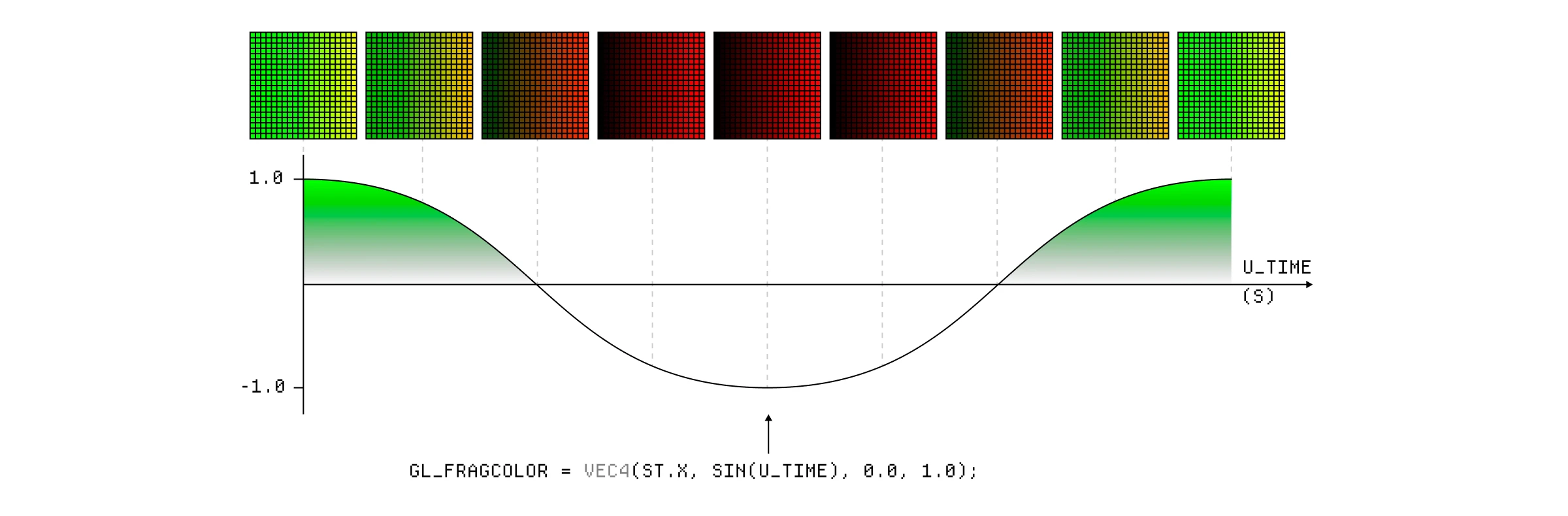
基于当前时间使用 sin() 函数动画化绿色分量。
除了这个基本示例之外,片段着色器更常用于为我们的几何体提供逼真的光照效果。对于我们的情况,我们想通过使用一种称为 Phong 光照的方法来近似一些现实世界的光照计算,从而为我们的立方体添加一个基本的光照设置。
Phong 光照是通过结合三种简单的光照技术创建的:
- 环境光 (Ambient lighting) — 创建一些均匀的、最小量的光。
- 漫反射光 (Diffuse lighting) — 基于光源的位置照亮我们的物体。
- 高光 (Specular lighting) — 基于光源和观察者之间的关系添加反射高光。
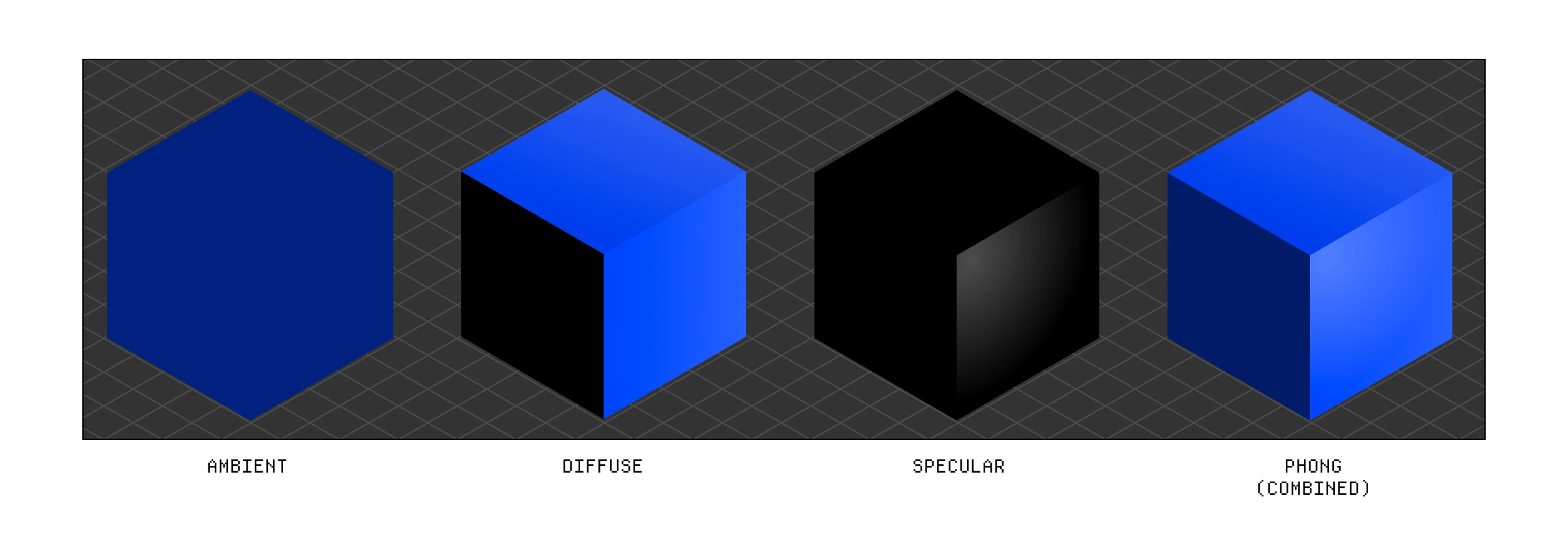
构成 Phong 光照效果的不同光照。
因为真正的光来自许多来源,从表面反弹和散射,所以物体基本上不可能完全黑暗。近似这种情况的一个非常廉价和简单的方法是创建一个环境光常量,我们将其应用于最终颜色,以便物体总是具有一些最小的亮度。
当然,光也有某种颜色或温度,所以我们将存储为 vec2 的光颜色乘以环境强度,然后在返回最终颜色之前将物体颜色乘以这个环境光。
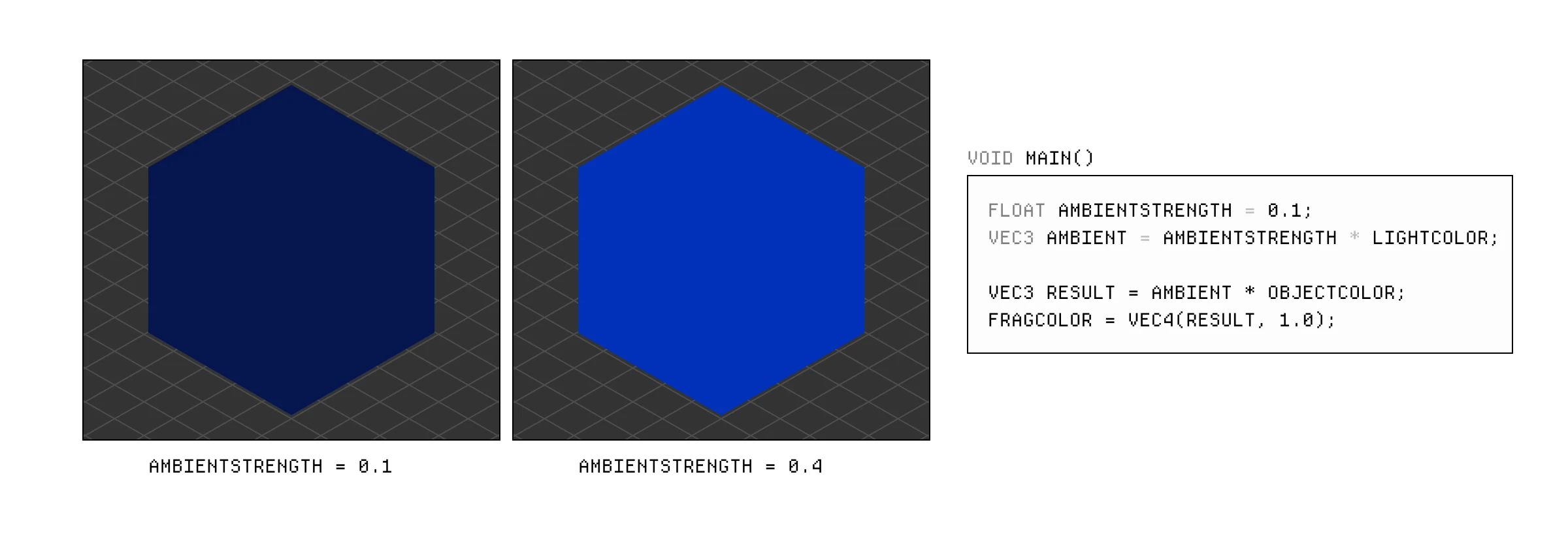
我们可以通过增加强度因子来改变环境光强度。
下一阶段更有趣。漫反射光根据特定片段相对于光源的角度使物体变亮。如果特定片段和光源之间的角度是垂直的,它将比处于更钝角时更亮。为此,我们需要先知道几件事:光源的位置、颜色和强度,以及特定片段朝向的方向。
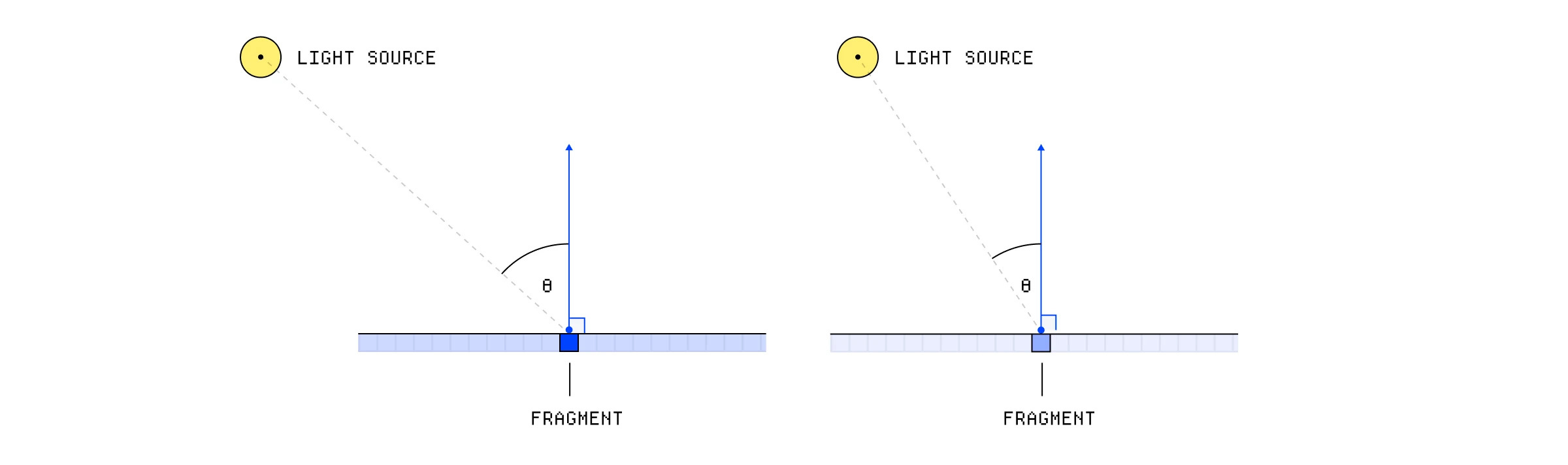
漫反射光根据表面和光源之间的角度改变片段亮度。
我们可以将光的位置、颜色和强度作为不同的 uniforms 存储并将该信息向下传递给我们的片段,这很容易。我们还可以通过获取两个位置之间的角度来计算光朝向我们片段的方向,但我们如何获得我们片段的方向?好吧,这就是我们在顶点着色部分简要提到的法线向量(Normal Vector)。
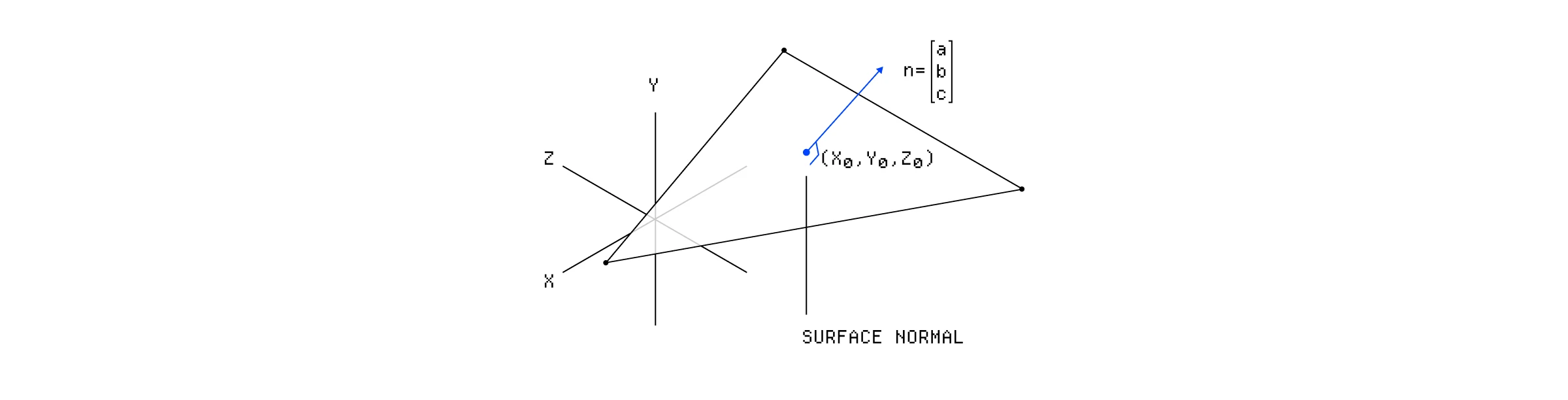
表面法线是垂直于表面指出的向量。
我们网格中的每个三角形都有一个表面法线,这是一个垂直于三角形面指出的单位向量。对于像我们的立方体这样的平面形状,我们可以只在光照计算中使用这个表面法线,因为该三角形中的每个片段都是一样的。
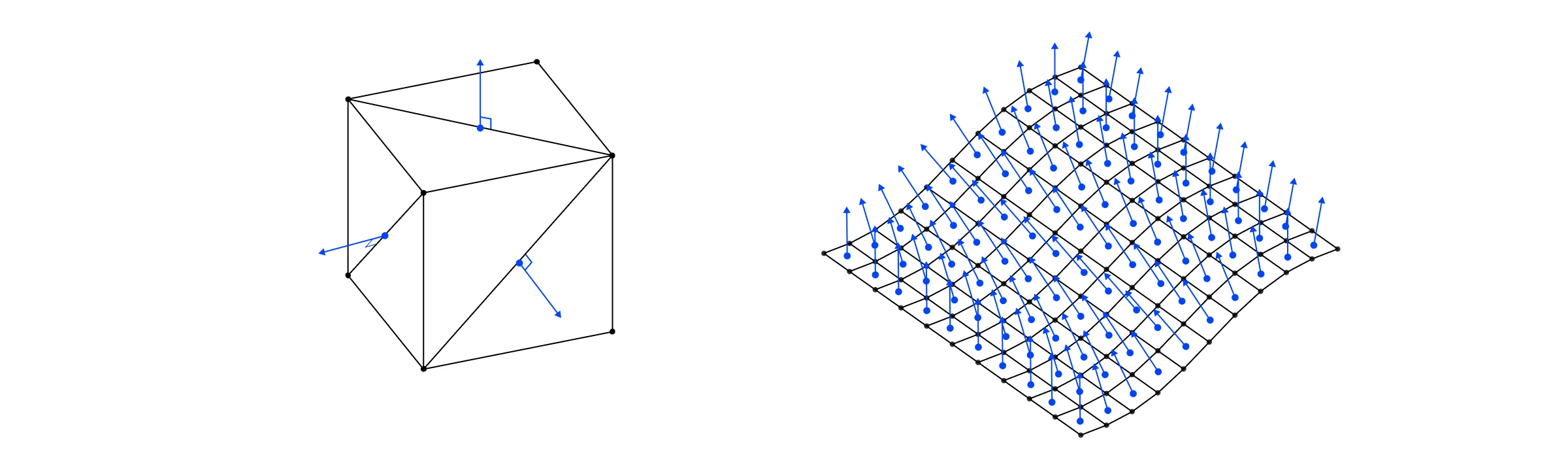
立方体和曲面的表面法线。
但是,如果我们试图为像球体这样的曲面着色呢?我们不想使用表面法线,因为它会为构成球体的每个表面创建平坦的着色。
在球体上进行平面着色的效果。
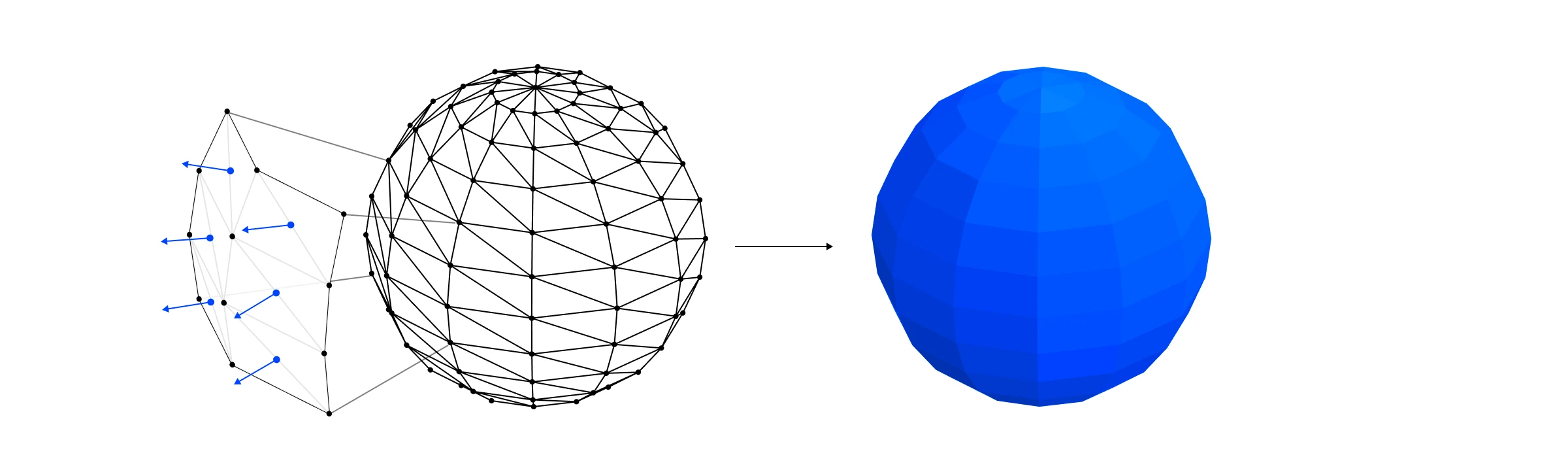
在这些情况下,我们希望通过平均周围三角形的表面法线来为三角形中的每个顶点创建法线。
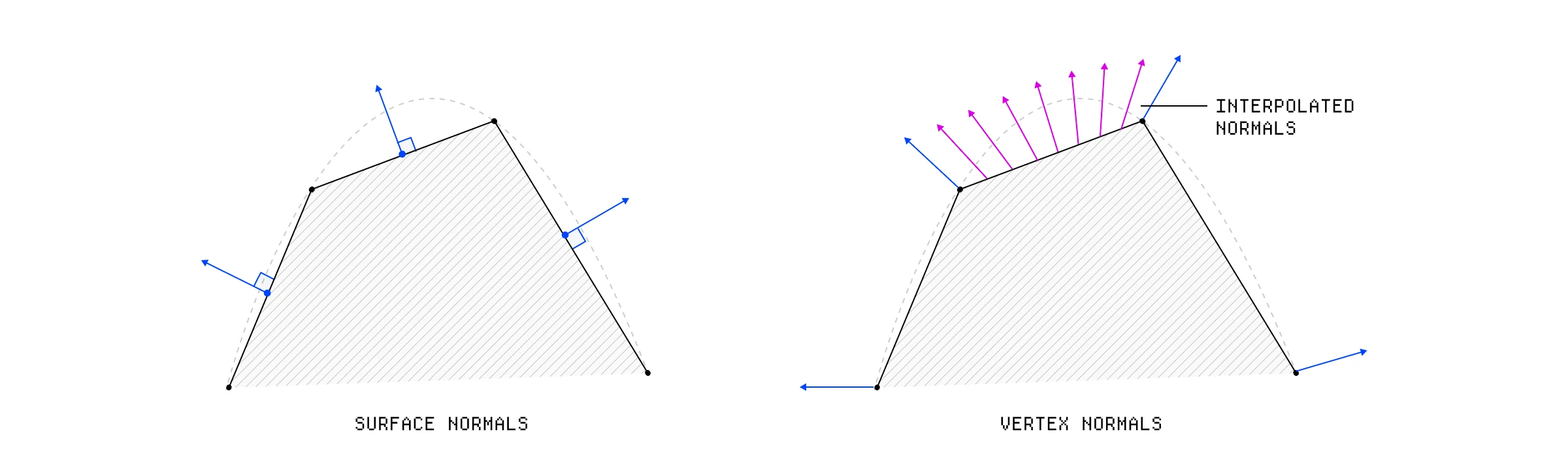
顶点法线是根据周围表面法线平均得出的。
然后我们可以将这些顶点法线作为 varyings 传递给我们的片段着色器,在那里它们将为每个片段进行插值,从而产生平滑曲面的效果,而无需我们要实际存储有关该曲线的信息。相当整洁。
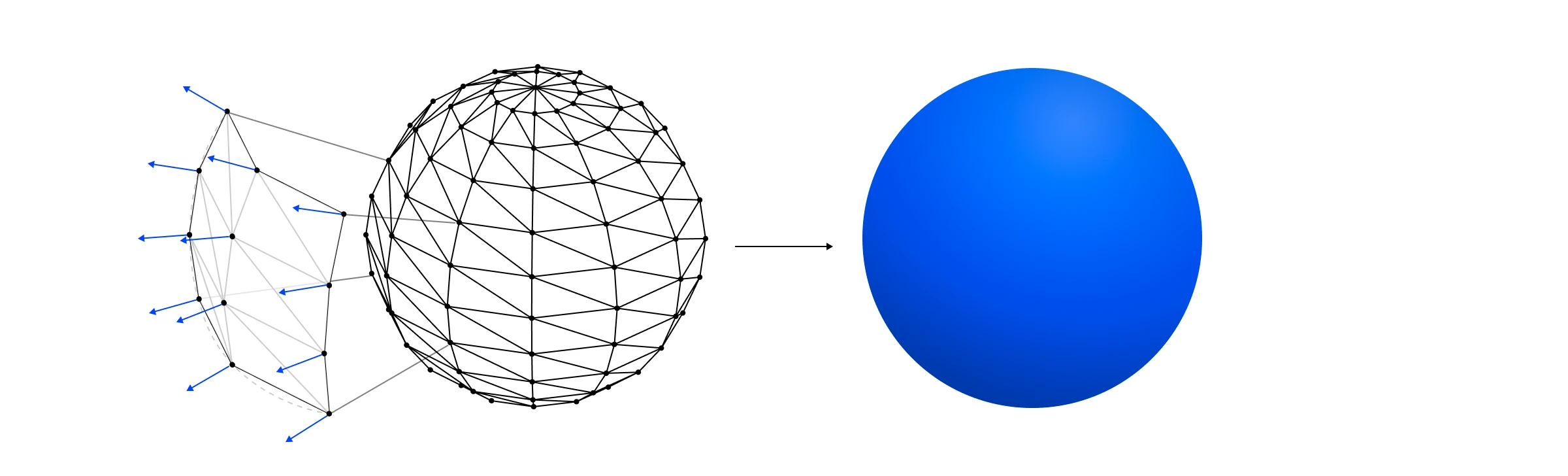
插值顶点法线允许我们平滑地为曲面着色。
回到我们的漫反射光照设置,现在我们有了片段的方向和光源的方向,我们可以使用这两个向量的点积来确定漫反射光照的强度。
点积是一种运算,它将两个长度相等的向量相乘并生成一个标量,该标量用于衡量两个向量指向同一方向的程度。当两个向量之间的角度为 90 度时,点积将为 0,它们之间的角度越锐利,点积就越接近 1。
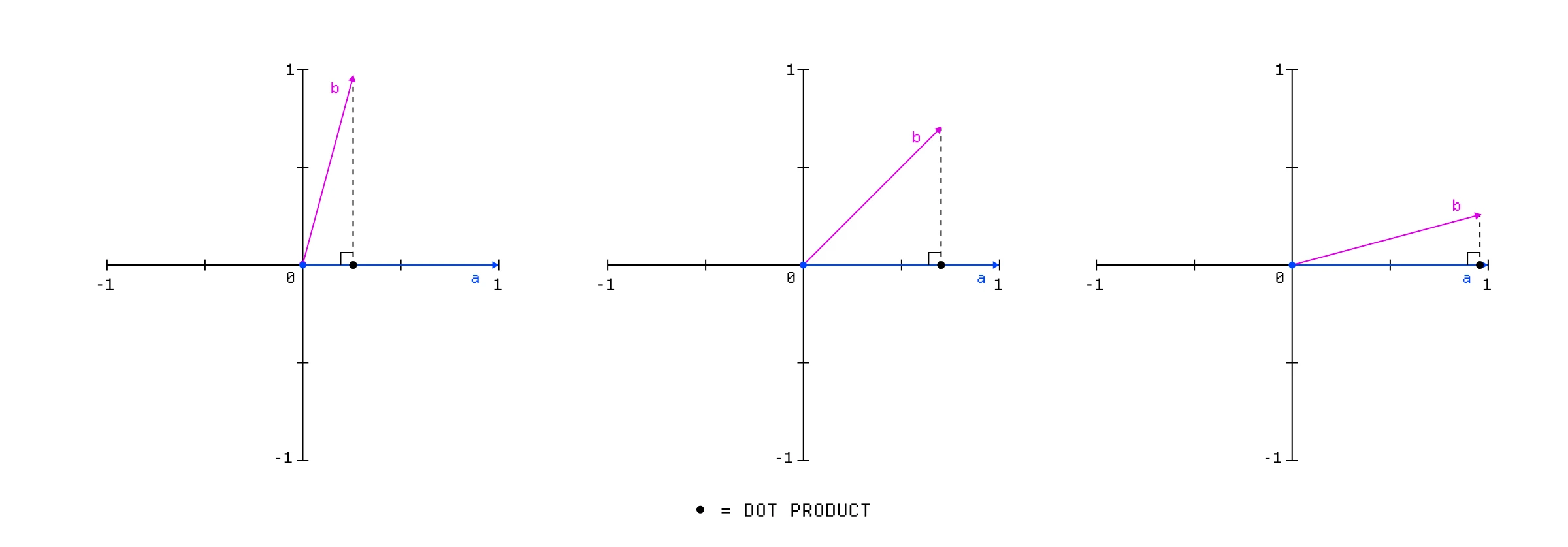
两个单位向量 a 和 b 的点积。
就像我们的环境光一样,我们将光的颜色乘以我们用点积计算的强度(我们限制它,使其永远不会变为负数)。然后我们将漫反射和环境结果加在一起,并将物体颜色乘以结果。
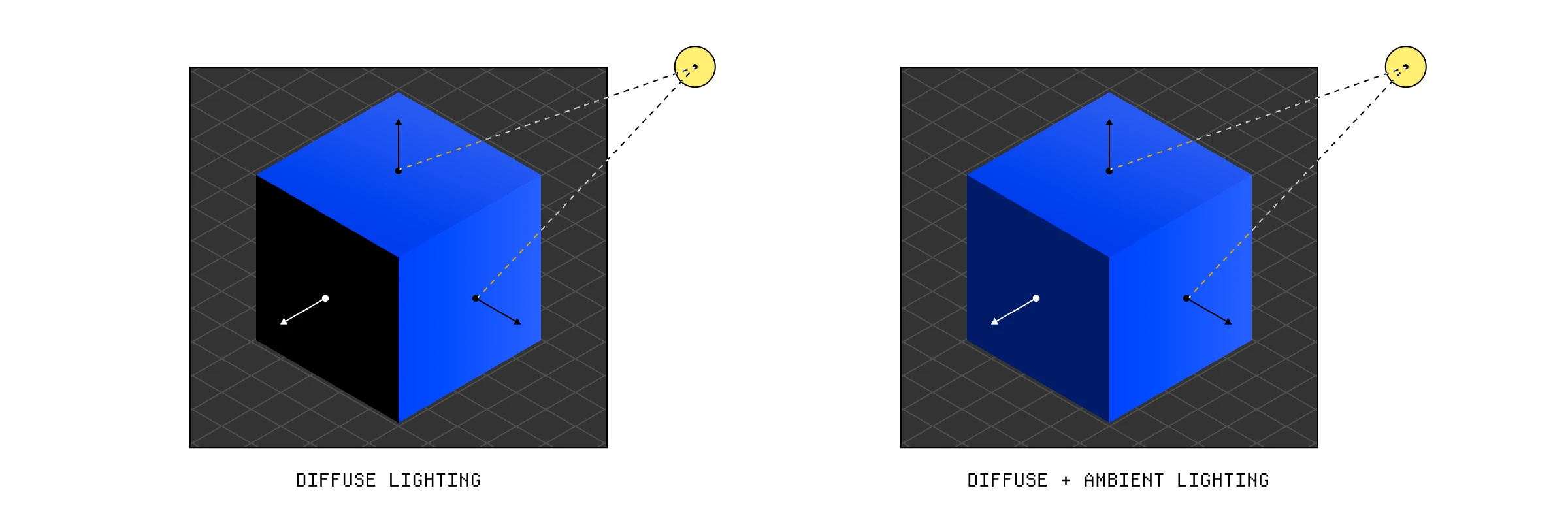
漫反射和环境光结合的效果。
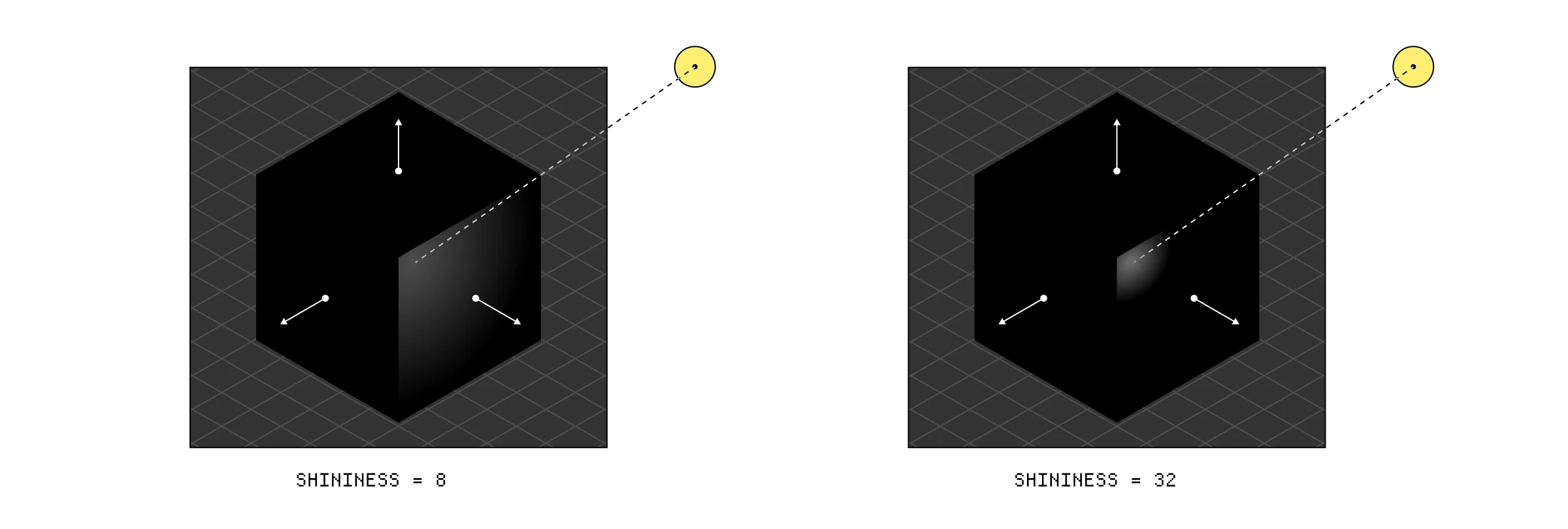
最后一步是高光(Specular lighting),它基本上是向表面添加反射高光,以模仿某些表面反射光源的方式。我们想要的高光量与我们试图模仿的材质的反射属性有关。像玻璃这样的材料比像木头这样的粗糙材料会显示更多的反射高光。
就像漫反射光一样,反射的强度基于光到表面的方向,但也基于观察者到表面的方向。反射离开表面的方向有点像光方向的镜像,随着反射方向和观察者方向的会聚,反射强度增加。
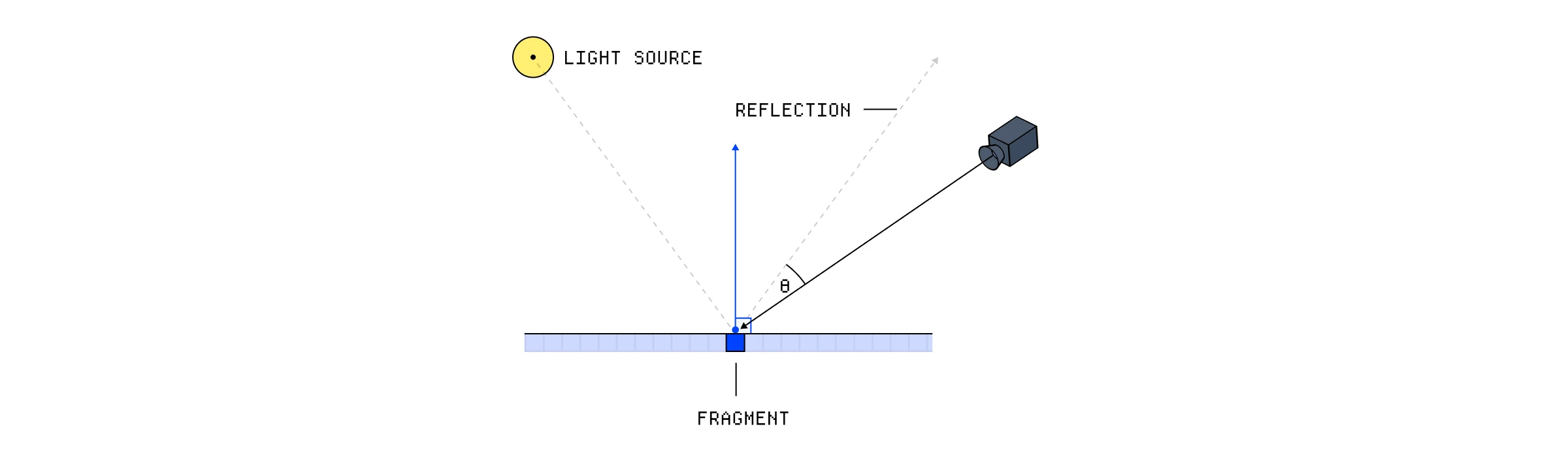
我们计算此所需的缺失部分是相机的位置,我们将其作为另一个 uniform 存储。然后我们可以使用它们的两个位置获取到片段的角度,这给了我们一个代表观察者方向的向量。
与之前类似,我们计算反射向量和观察者向量的点积以给我们强度值。然后我们将它提升到 8 次方,这代表表面的**光泽度(shininess)**值——这个值越高,反射就越小且越不扩散——并再次将所有这些乘以强度因子和光的颜色。
最后,我们将此添加到我们的环境光和漫反射光中,并将其乘以物体颜色。
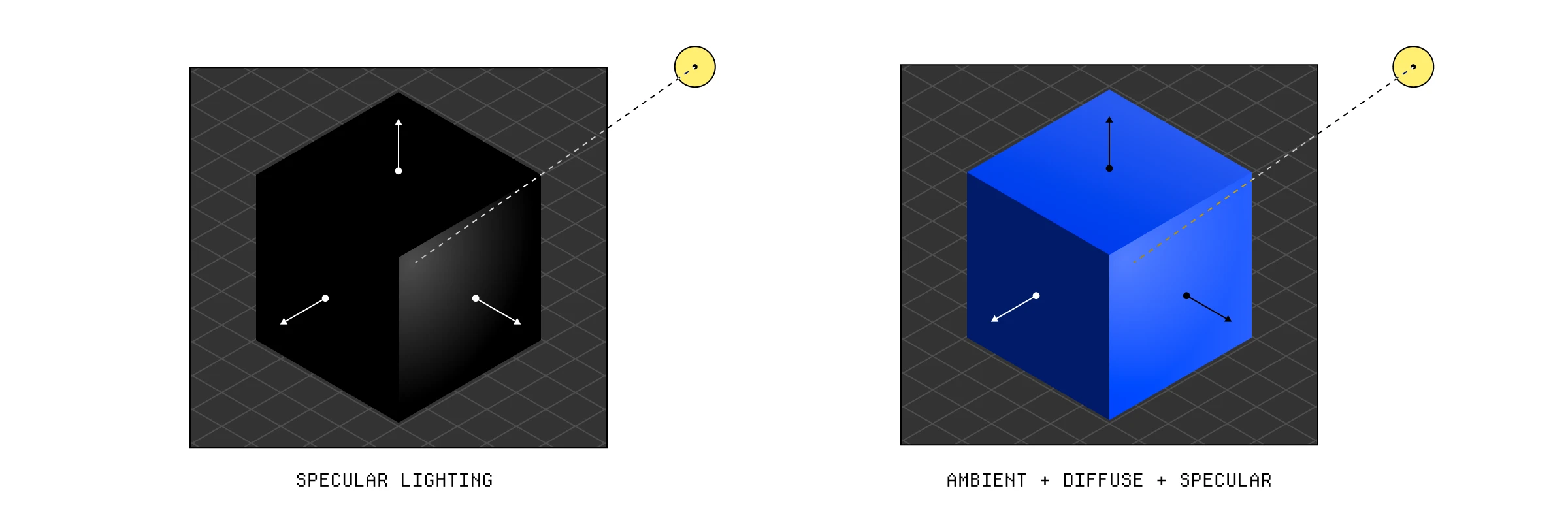
一旦我们将所有效果加在一起,我们就得到了 Phong 光照模型。
那是很多细节,但我认为它证明了片段着色是多么灵活和强大。幸运的是,当你使用 3D 软件时,你使用的材质会免费获得这些光照效果,所以你可能永远不必担心这种东西。
片段着色器完成后,我们将片段写入帧缓冲区,以便显示控制器读取并在屏幕上渲染。在每个片段写入帧缓冲区之前,它将进行一些可见性测试,比如我们要谈到的深度测试或模板测试。
模板测试(Stencil Test)用于遮罩或剪切之类的操作,我们检查像素的坐标是否落在模板的边界之外,如果是,我们再次退出。我们还在这个阶段处理混合和不透明度之类的事情,所以我们可能会根据光栅化器的抗锯齿结果将片段输出与帧缓冲区中的值混合。
编写着色器 (Writing shaders)
如果着色器还不够复杂,如果你打算自己开始编写一些,还需要注意一堆其他东西。
让我们从它们运行的环境开始——除非你是一个绝对的怪人并且可以直接在 GPU 上编写机器代码,否则你需要通过某种 API 与 GPU 交互。历史上,我们一直使用这个名为 OpenGL 的跨平台 API,它允许我们与 GPU 交互并用各种不同的语言摆弄渲染管线。
制作 OpenGL 的同一群人也开发了一种专门用于编写着色器的语言,称为 GLSL,这是一种类似 C 的语言,由图形驱动程序在运行时编译。你在网上找到的大多数着色器代码都是用 GLSL 编写的。OpenGL 有一个 Web 实现,允许我们编写可以与 GPU 交互的 Web 应用程序,称为 WebGL。
但是,当然,没有什么是非常简单的。微软有自己的图形 API 叫 DirectX 或 Direct3D,他们有自己的面向对象的着色器语言叫 HLSL,它是预先编译成可执行文件的。苹果为其硬件拥有自己的图形 API 层叫 Metal,带有另一种特定的着色器语言叫 MSL。
哦,顺便说一句,OpenGL 被认为是过时的,并被一种叫 Vulkan 的东西所取代,而 WebGL 正在被不再支持 GLSL 的 WebGPU 所取代。太棒了。
好消息是,你极不可能直接与这些东西中的任何一个交互,并且有互操作层可以保持一切顺利运行。如果你像我一样,你会用像 Three.js 这样的东西编写着色器,它使用 WebGL/WebGPU,而 WebGL/WebGPU 又会根据浏览器和操作系统与底层 API 之一进行交互。
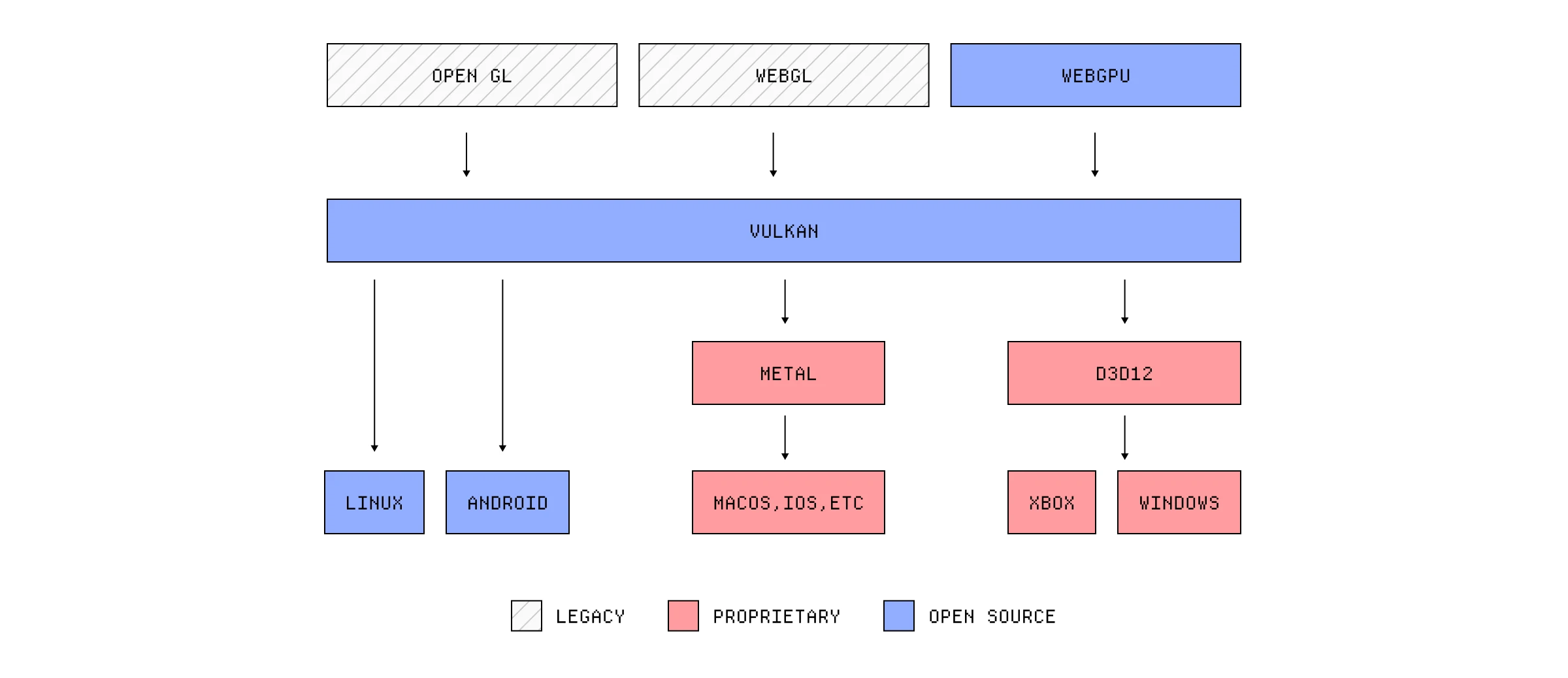
各种图形 API 如何互操作。
不仅仅是 3D 图形渲染可以从在 GPU 上运行中受益——还有很多其他类型的工作可以从被拆分并并行运行中受益。问题是,我们刚刚描述的图形渲染管线对于该类型的问题来说是非常定制化的。
较新的 API 引入了计算着色器(Compute Shaders),这是一种在该管线之外运行但仍有能力与之交互的着色器。想象一下我们想要渲染一个依赖于物理模拟的 3D 粒子系统。更新每个粒子的顶点位置会消耗大量 CPU 资源,所以相反,我们可以将其卸载到计算着色器,并在顶点着色器阶段将这些值馈送到管线中。
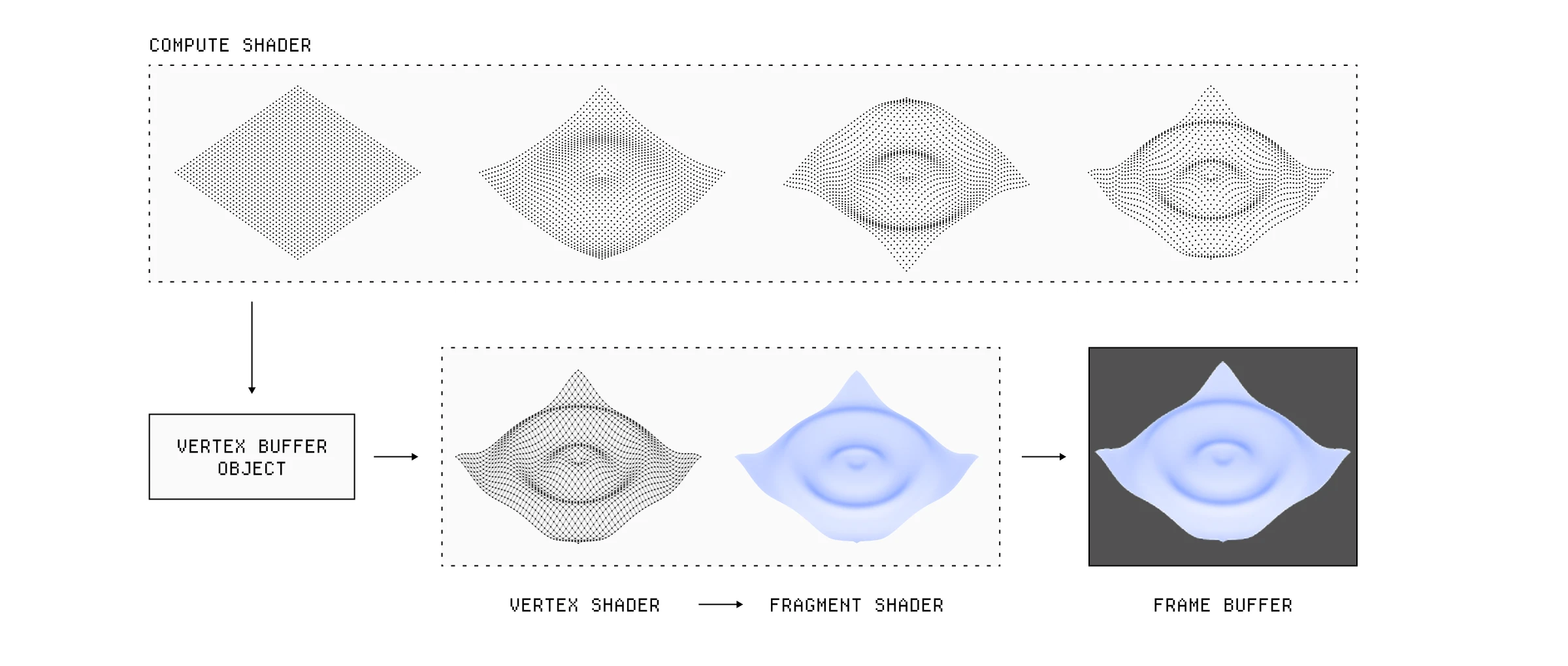
计算着色器可以独立于图形管线运行,同时仍与之通信。
除了更快之外,因为粒子位置可以并行计算,这还有一个额外的优势,即所有顶点位置都存储在 GPU 内存中,因此 GPU 访问它们要快得多。
还有 CUDA(计算统一设备架构),这是 NVIDIA GPU 的一组 API,允许你在图形渲染管线之外使用 GPU 进行计算。这通常用于运行 AI/ML 模型,这是非常并行的问题,需要完全在渲染管线之外运行。
为了防止你迷失方向,这里是所有不同 API 的摘要:
| 技术 | 公司 | 平台 | 图形或计算 |
|---|---|---|---|
| OpenGL* | Khronos Group | 跨平台 | 图形 (+ 新版本中通过计算着色器进行计算) |
| WebGL* | Khronos Group | 浏览器 | 图形 |
| Vulkan | Khronos Group | 跨平台 | 两者皆有 |
| WebGPU | Khronos Group | 浏览器 | 两者皆有 |
| Metal | Apple | Apple 平台 | 两者皆有 |
| Direct3D | Microsoft | Windows 和 Xbox | 图形 (+ 通过计算着色器进行计算) |
| CUDA | NVIDIA | NVIDIA GPU | 计算 |
_ * 被视为遗留技术_
所以,这就是对一个相当简单的问题的漫长而复杂的回答。总而言之,着色器酷毙了,但它们需要从编写按顺序运行的软件转变思维方式。我认为学习图形管线很重要的原因是因为它让这种转变容易了一些。
幸运的是,在像 Three.js 这样的框架和越来越擅长编写着色器代码的 AI 之间,自己摆弄着色器从未如此简单。
术语表 (Glossary)
| 英文 (English) | 中文 (Chinese) | 描述 |
|---|---|---|
| Anti-Aliasing | 抗锯齿 | 计算机图形学中使用的一种技术,通过平滑像素颜色来减少曲线或对角线上的锯齿状边缘。 |
| Buffer | 缓冲区 | 用于临时存储数据的内存区域,通常用于在 CPU 和 GPU 之间或图形管线的不同阶段之间传输数据。 |
| Compute Shader | 计算着色器 | 一种在 GPU 上执行通用计算任务(不限于图形渲染)的着色器,支持数据的并行处理。 |
| Dot Product | 点积 | 一种数学运算,将两个向量相乘并返回一个标量值,通常用于衡量两个向量的对齐程度。 |
| Fragment | 片段 | 光栅化过程中生成的潜在像素,包含颜色和深度等数据,由片段着色器处理以生成最终的像素颜色。 |
| Fragment Shader | 片段着色器 | 一种计算屏幕上每个像素(片段)最终颜色的着色器,通常应用纹理、光照和其他视觉效果。 |
| Framebuffer | 帧缓冲区 | 存储正在渲染的图像数据的完整帧的内存区域,这些数据将显示在屏幕上。 |
| GPU | 图形处理单元 | 专门设计的硬件,用于同时处理许多并行操作,特别是在渲染图形和执行计算密集型任务方面。 |
| GUI | 图形用户界面 | 一种可视界面,允许用户使用窗口、图标和按钮等图形元素与计算机或软件进行交互。 |
| Matrix Multiplication | 矩阵乘法 | 一种通过相乘两个矩阵生成新矩阵的数学运算,常用于图形学和线性代数中以变换坐标。 |
| Normal | 法线 | 垂直于表面的向量,在 3D 图形中用于确定光线如何与该表面相互作用。 |
| Phong Lighting | Phong 光照 | 3D 计算机图形学中使用的一种着色技术,用于模拟光线与表面相互作用的方式,产生逼真的高光和阴影。 |
| Texture | 纹理 | 应用于 3D 模型表面的位图图像,赋予其颜色和细节。 |
| Uniform | 统一变量 | 着色器程序中的全局变量,在单次绘制调用期间对着色器的所有实例保持不变。 |
| Unit Vector | 单位向量 | 长度(模)为 1 的向量,用于表示方向而不进行缩放。 |
| Varying | 易变变量 | 在着色器阶段之间插值的变量,将数据从顶点着色器传递到片段着色器,值在表面上平滑混合。 |
| Vector | 向量 | 既有大小又有方向的量,通常表示为 2D 或 3D 空间中的箭头。 |
| Vertex | 顶点 | 定义几何形状角点或交叉点的 3D 空间中的点,用作 3D 建模和图形的基本构建块。 |
| Vertex Shader | 顶点着色器 | 处理 3D 几何中每个顶点的着色器,通常用于变换顶点位置并将数据传递给后续管线阶段。 |
| Z-Buffer | 深度缓冲区 | 一种在 3D 图形中存储像素深度信息的缓冲区,用于处理遮挡并确定场景中哪些物体是可见的。 |